- Why Building a URL Shortener Taught Me Everything About Cloud Architecture
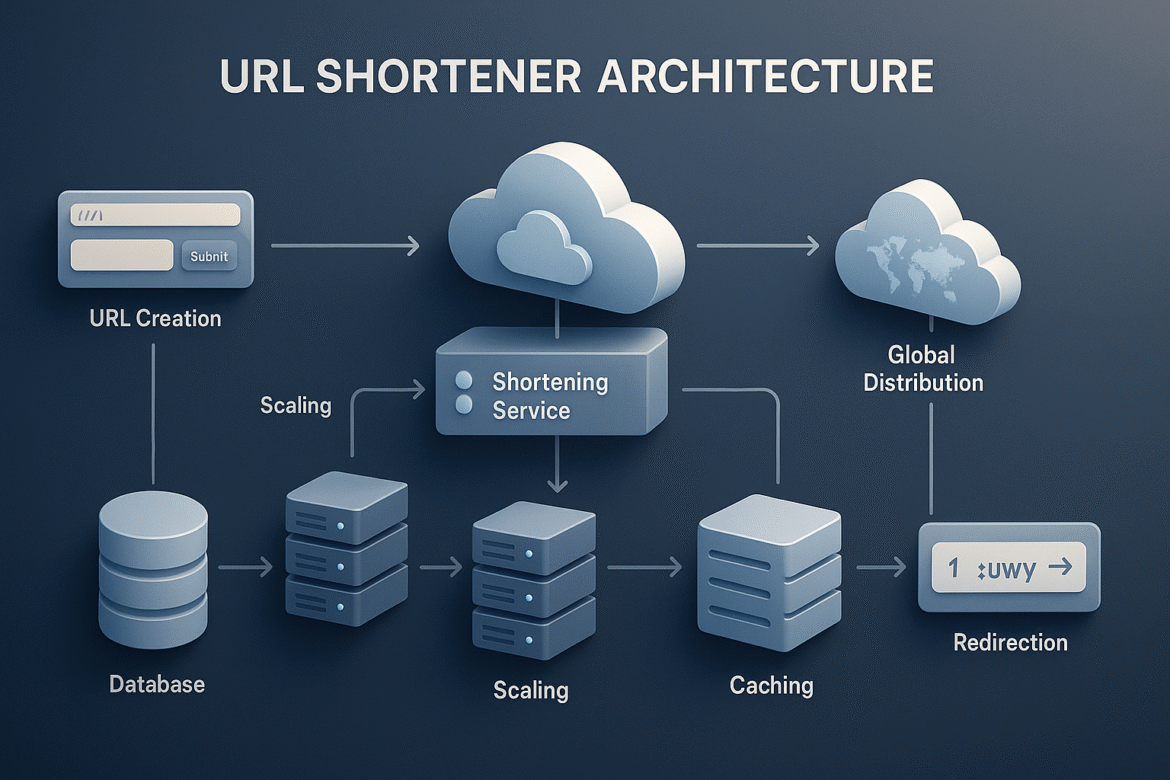
- From Napkin Sketch to Azure Blueprint: Designing Your URL Shortener’s Foundation
- From Architecture to Implementation: Building the Engine of Scale
- Analytics at Scale: Turning Millions of Click Events Into Intelligence
- Security and Compliance at Scale: Building Fortress-Grade Protection Without Sacrificing Performance
- Performance Optimization and Cost Management: Engineering Excellence at Sustainable Economics
- Monitoring, Observability, and Operational Excellence: Building Systems That Tell Their Own Story
- Deployment, DevOps, and Continuous Integration: Delivering Excellence at Scale

Part 2 of the “Building a Scalable URL Shortener on Azure” series
In our previous post, we discovered that building a URL shortener for 100 million URLs per day is like designing a bridge for millions of cars – the scale transforms a simple concept into a complex engineering challenge. We broke down the math: 10,000+ URL creations per second during peak times, up to 1 million redirects per second, and 11TB of annual data growth.
Now comes the critical question that every architect faces: which cloud services should you choose, and why?
Today, we’re going to transform our scale requirements into concrete Azure service selections. Think of this as moving from a napkin sketch to architectural blueprints – we need to make decisions that will either support our system for years or haunt us at 3 AM when everything is on fire.
The Foundation Decision: Why Platform Services Beat Infrastructure Services
When faced with building at scale, many engineers instinctively reach for virtual machines and containers because they feel familiar and controllable. This instinct is understandable but often wrong for production systems, especially when you’re not Google or Netflix with dedicated platform teams.
Here’s the key insight that changed how I think about cloud architecture: your competitive advantage isn’t running databases or managing load balancers – it’s solving business problems faster than your competitors.
Azure offers three layers of services, and understanding when to use each layer determines whether you’re building a maintainable system or creating technical debt:
Infrastructure as a Service (IaaS): Virtual machines, storage, networking. You control everything, which means you’re responsible for everything. Think of this as buying raw materials to build your own furniture.
Platform as a Service (PaaS): Managed databases, app hosting, message queues. Azure handles the operational complexity while you focus on your application logic. This is like buying high-quality furniture components and assembling them into exactly what you need.
Software as a Service (SaaS): Complete applications like Office 365. You use the service but can’t customize the underlying functionality. This is like buying finished furniture – it works immediately but doesn’t meet custom requirements.
For our URL shortener, PaaS services provide the sweet spot between control and operational simplicity. Let me show you how this plays out in practice.
Application Layer: Azure App Service vs. Container Orchestration
The first major decision involves hosting our API. We could deploy containers to Azure Kubernetes Service for maximum flexibility, or use Azure App Service for operational simplicity. This decision ripples through every other architectural choice we make.
The Container Temptation
Kubernetes appeals to engineers because it feels powerful and flexible. You can optimize every aspect of deployment, scaling, and resource utilization. It’s like having a Formula 1 race car – incredibly capable in the right hands.
But here’s what I learned from production outages: Kubernetes requires dedicated expertise to operate reliably. When your URL shortener is down at 2 AM, you need someone who understands pod networking, service mesh configuration, and cluster autoscaling. Unless you’re building a platform for dozens of applications, this complexity rarely pays off.
The App Service Advantage
Azure App Service might seem less sophisticated, but it handles the operational complexity that keeps you awake at night. Think of it as choosing a reliable Toyota over a high-maintenance sports car – it might not win races, but it gets you to work every day without drama.
Here’s what App Service gives you out of the box that would take weeks to configure properly in Kubernetes:
Automatic SSL certificate management – certificates renew themselves, no midnight alerts about expired certificates.
Built-in deployment slots – you can test new versions in production infrastructure before switching traffic over. This blue-green deployment capability prevents the “it worked on my machine” disasters.
Integrated monitoring and logging – every request, exception, and performance metric flows automatically to Azure Monitor without configuration.
Auto-scaling based on real metrics – CPU, memory, and request queue depth trigger scaling decisions, not guesswork about load patterns.
Most importantly, App Service scales to handle our peak traffic requirements without requiring a dedicated platform team. When Reddit discovers your service and sends 50,000 simultaneous users, App Service scales automatically while you focus on handling the business impact rather than keeping servers alive.
Database Architecture: The Foundation That Everything Builds On
Database selection might be the most critical architectural decision you make because changing it later requires migrating terabytes of data with zero downtime. Get this wrong, and you’ll spend months fixing it while your competitors capture market share.
The NoSQL Temptation
Many engineers immediately reach for NoSQL databases like Cosmos DB because they associate them with “web scale.” This instinct comes from stories about how Google and Amazon built their own distributed databases to handle massive scale.
But here’s the nuanced truth: NoSQL databases excel at specific use cases, particularly when you need eventual consistency and can partition data cleanly. However, our URL shortener has requirements that favor traditional SQL databases.
Why Azure SQL Database Wins for URL Shorteners
Remember our core requirement: we need to generate unique short codes without collisions. This requires atomic operations that either succeed completely or fail completely – exactly what ACID transactions provide.
Consider what happens when two users simultaneously try to shorten the same URL during a traffic spike. With SQL transactions, we can atomically check for existing mappings and create new ones without race conditions. NoSQL databases handle this scenario with complex application logic or accept eventual consistency, neither of which works well for URL generation.
Azure SQL Database provides additional advantages that directly address our scale requirements:
Computed columns for base62 encoding – we can generate short codes directly in the database using computed columns, guaranteeing uniqueness while keeping the logic close to the data.
Read scale-out capabilities – our redirect operations can use read-only replicas while URL creation uses the primary database. This separation ensures that high redirect volume never impacts URL generation performance.
Automatic performance tuning – Azure SQL Database learns your query patterns and automatically adjusts indexes, statistics, and execution plans. It’s like having a database administrator who never sleeps and knows your workload intimately.
Here’s how our core database schema leverages these SQL advantages:
-- The foundation table that everything builds upon
CREATE TABLE urls (
-- Auto-incrementing ID ensures uniqueness and enables base62 encoding
id BIGINT IDENTITY(1,1) PRIMARY KEY,
-- Computed column automatically generates short codes from IDs
-- This approach guarantees uniqueness without complex collision handling
short_code AS (dbo.base62_encode(id)) PERSISTED,
original_url NVARCHAR(2000) NOT NULL,
created_at DATETIME2(3) DEFAULT SYSUTCDATETIME(),
expires_at DATETIME2(3) NULL,
is_active BIT DEFAULT 1,
-- Indexes optimized for our specific query patterns
INDEX ix_short_code NONCLUSTERED (short_code)
INCLUDE (original_url, is_active, expires_at),
INDEX ix_expires_at NONCLUSTERED (expires_at)
WHERE expires_at IS NOT NULL AND is_active = 1
);The beauty of this approach lies in its simplicity. The database handles uniqueness guarantees, the computed column eliminates race conditions in short code generation, and the indexes optimize our two primary query patterns: URL creation and redirect lookup.
Caching Strategy: The Performance Multiplier
Here’s where many architectures either excel or collapse under load: caching strategy. Done well, caching can reduce your database load by 90% while improving response times from hundreds of milliseconds to single digits. Done poorly, caching becomes a source of data corruption and cache invalidation nightmares.
Understanding Cache Hierarchies
Think of caching like a memory hierarchy in computer architecture. Different cache layers have different characteristics: speed, capacity, and consistency guarantees. The key insight is matching the right cache layer to the right use case.
Level 1: Application Memory Cache – Microsecond access times for the most popular URLs, but limited to single server instances.
Level 2: Azure Cache for Redis – Millisecond access times shared across all application instances, with much larger capacity.
Level 3: Azure Front Door Edge Cache – Global distribution with the highest capacity, but limited control over cache invalidation.
The Power Law of URL Popularity
URL access patterns follow a power law distribution that makes caching incredibly effective. A small percentage of URLs receive the vast majority of traffic. That viral TikTok link or breaking news article might get clicked millions of times within hours.
This distribution means that a relatively small cache can handle the majority of redirect requests. Our Level 1 cache might store only 10,000 URLs but handle 70% of all redirect traffic. Level 2 cache with 100,000 URLs might handle 95% of requests.
Understanding this pattern shapes our entire caching architecture. We optimize aggressively for cache hits because they represent the common case, while ensuring that cache misses (the minority) still perform acceptably.
// Multi-tiered caching that leverages the power law distribution
public async Task<string> GetUrlAsync(string shortCode)
{
// Level 1: Check application memory (fastest)
if (_localCache.TryGetValue($"url:{shortCode}", out string cachedUrl))
{
return cachedUrl; // Microsecond response time
}
// Level 2: Check distributed Redis cache
var redisResult = await _redisCache.StringGetAsync($"url:{shortCode}");
if (redisResult.HasValue)
{
// Warm the local cache for future requests
_localCache.Set($"url:{shortCode}", redisResult, TimeSpan.FromMinutes(5));
return redisResult; // Millisecond response time
}
// Level 3: Database lookup (fallback)
var originalUrl = await _database.GetUrlByShortCodeAsync(shortCode);
if (originalUrl != null)
{
// Warm both cache layers for future requests
await _redisCache.StringSetAsync($"url:{shortCode}", originalUrl, TimeSpan.FromHours(1));
_localCache.Set($"url:{shortCode}", originalUrl, TimeSpan.FromMinutes(5));
}
return originalUrl;
}This hierarchical approach means that popular URLs get served from memory, moderately popular URLs come from Redis, and only new or rarely accessed URLs require database queries.
Security Foundations: Defense in Depth
Security at scale requires systematic approaches rather than hoping nobody finds your service. The challenge with URL shorteners is that we’re essentially creating a service that can redirect users anywhere on the internet, making us a potential vector for malicious attacks if we’re not careful.
The Principle of Defense in Depth
Rather than relying on a single security measure, we implement multiple layers of protection. If one layer fails, other layers continue protecting the system. Think of it like a medieval castle with multiple walls, moats, and guard towers – attackers must defeat multiple defenses simultaneously.
Azure API Management as the First Line of Defense
Azure API Management sits in front of our App Service and handles security policies before malicious requests reach our application code. This separation of concerns keeps our business logic clean while ensuring consistent security policy enforcement.
Rate limiting becomes particularly critical for URL shorteners because they’re attractive targets for abuse. A malicious actor could generate millions of short URLs to overwhelm our system or create redirect loops to cause denial of service attacks.
Input Validation and URL Scanning
Every URL submitted for shortening must pass validation checks that go beyond simple format verification. We need to check submitted URLs against known malware databases, validate that they point to legitimate websites, and ensure they don’t create redirect loops back to our own service.
This validation process runs asynchronously to avoid impacting URL creation performance, but suspicious URLs get flagged immediately for manual review.
Regional Distribution: Thinking Globally from Day One
One of the most valuable lessons I learned building systems at scale is that global distribution should be architectural from the beginning, not retrofitted later. Users expect fast response times regardless of their geographic location, and modern applications compete on performance as much as features.
Azure’s Global Infrastructure Advantage
Azure operates data centers in over 60 regions worldwide, providing a foundation for globally distributed applications. The key insight is that we can leverage this infrastructure without managing the complexity ourselves.
Azure Front Door acts as our global entry point, routing users to the nearest healthy region while providing integrated caching and security filtering. Users in Japan get served from Azure’s Japan regions, while European users connect to Azure’s European data centers.
This geographic distribution provides both performance and reliability benefits. Regional outages affect only users in that specific area, while other regions continue operating normally.
What We’ve Built and What’s Next
In this post, we’ve made the fundamental architectural decisions that will support our URL shortener through massive scale:
Azure App Service provides operational simplicity while handling auto-scaling and deployment complexity automatically.
Azure SQL Database gives us ACID transactions for reliable URL generation plus read scale-out for high redirect volume.
Multi-tiered caching with Azure Cache for Redis leverages the power law distribution of URL popularity to achieve 90%+ cache hit rates.
Defense-in-depth security protects against malicious URLs and abuse while maintaining fast response times for legitimate users.
Global distribution with Azure Front Door provides fast response times worldwide while building in regional failover capabilities.
These foundation decisions create a robust platform that can grow with our requirements. But we’re just getting started. In our next post, we’ll dive deep into the implementation details that turn these architectural decisions into working code.
Coming Up in Part 3: “From Architecture to Implementation”
Next week, we’ll explore the fascinating technical details of base62 encoding for URL generation, implement the multi-tiered caching system with Azure Cache for Redis, and build the API endpoints that handle millions of requests per second. We’ll also tackle the tricky problem of cache invalidation and data consistency across multiple regions.
We’ll see how seemingly simple operations like “generate a short code” become sophisticated algorithms when you’re handling thousands of requests per second, and how proper error handling can mean the difference between graceful degradation and cascading failures.
This is Part 2 of our 8-part series on building scalable systems with Azure. Subscribe to stay updated as we continue exploring advanced topics like analytics pipelines, security hardening, and cost optimization strategies that keep high-scale applications both performant and profitable.
Series Navigation:
← Part 1: Why Building a URL Shortener Taught Me Everything About Scale
→ Part 3: From Architecture to Implementation – Coming Next Week