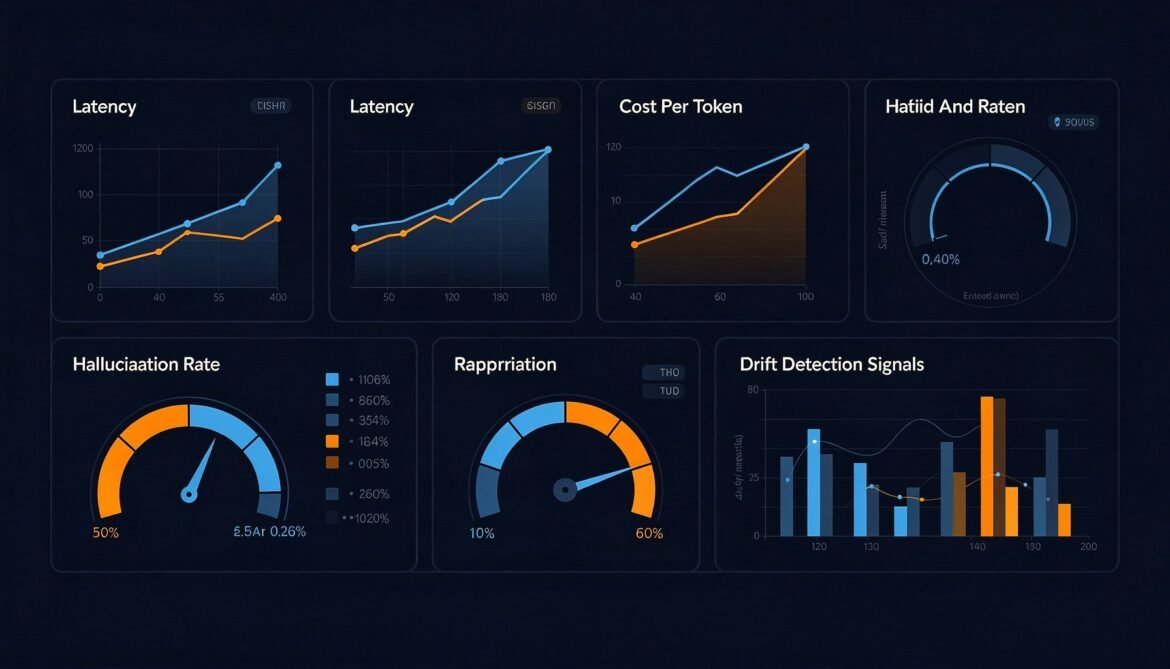
Uptime and error rate are not enough. This post covers the metrics that actually reveal whether your LLM is working correctly in production — time-to-first-token, cost per request, hallucination rate indicators, output drift, and how to build dashboards that catch silent failures before users do.
Tag: prometheus

Production Operations and Distributed Deployment: Monitoring, Versioning, and Maintaining Edge AI at Scale
Comprehensive production operations guide for distributed edge AI deployments. Covers Prometheus/Jaeger monitoring integration, data drift detection with statistical analysis, model versioning and registry management, canary deployment with automated rollback, OTA update orchestration, and fleet management patterns for 100+ edge devices.
Advanced PM2 Monitoring, Logging, and Alerting Systems
Master advanced PM2 monitoring with PM2 Plus, Prometheus integration, centralized logging, and custom alerting systems. Build comprehensive dashboards for production monitoring.
Advanced Kafka Message Monitoring: Enterprise Solutions with Prometheus and Grafana
Continuing from our previous guide on identifying unused messages in Kafka, this article focuses on advanced monitoring techniques, automated alerting systems, and C# implementations for



