With your Azure AI Foundry development environment properly configured, you are ready to build your first autonomous agent using Semantic Kernel. This article provides comprehensive guidance for creating single-agent systems that can reason, make decisions, and execute actions across Python, Node.js, and C# implementations.
Semantic Kernel serves as Microsoft’s enterprise-ready orchestration framework for building AI agents. Version 1.0 launched in 2024 after extensive preview usage, converging with AutoGen in late 2024 to form the foundation of Microsoft Agent Framework. This convergence combines Semantic Kernel’s production-ready stability with AutoGen’s innovative multi-agent patterns, creating a unified platform for agent development.
Understanding Semantic Kernel Agent Architecture
Semantic Kernel agents operate through a flexible architecture that separates concerns between agent logic, AI services, and external capabilities. At the core sits the Kernel object that manages AI service connections, orchestrates plugin execution, and maintains execution context. This object serves as the central coordination point for all agent operations.
Agents in Semantic Kernel come in several specialized types. The ChatCompletionAgent provides straightforward conversational capabilities powered by chat completion models like GPT-4. This agent type works well for interactive dialogue scenarios without requiring the full assistant API infrastructure.
The AzureAIAgent integrates directly with Azure AI Foundry Agent Service, providing advanced capabilities including automatic tool calling without manual parsing, secure conversation thread management, built-in tools like code interpreter and file search, and integration with Bing, Azure AI Search, and Azure Functions. This agent type is recommended for production Azure deployments requiring enterprise features.
OpenAIAssistantAgent connects to OpenAI’s Assistant API for sophisticated conversational AI with tool usage and file handling. The AzureAssistantAgent extends this specifically for Azure OpenAI deployments with Azure-specific authentication.
Plugin architecture enables agents to interact with external systems and execute custom business logic. Plugins group related functions together, mirroring how enterprise developers already structure services and APIs. Each plugin contains functions with semantic descriptions that AI models use to determine which function to invoke for a given task.
Creating Your First Agent in Python
Python development with Semantic Kernel begins by importing required packages and configuring the Azure AI connection. Ensure you have installed semantic-kernel with the azure extra using pip install semantic-kernel[azure] as described in Part 2 of this series.
Create a new Python file named simple_agent.py in your project directory. Import necessary modules including asyncio for asynchronous operations, DefaultAzureCredential for authentication, and AzureAIAgent for Azure AI Foundry integration. Load environment variables from your .env file using python-dotenv.
The AzureAIAgent creation process requires establishing a client connection to your Azure AI Foundry project, creating an agent definition on the Azure AI Agent Service, and wrapping that definition in a Semantic Kernel agent instance. The client connection uses DefaultAzureCredential which automatically uses your Azure CLI authentication during development and managed identity in production.
Agent definition specifies the model deployment to use, typically the GPT-4o-mini deployment created in Part 2. Provide a name identifying the agent and instructions that define the agent’s behavior and personality. Instructions should be clear and specific, describing what the agent does, how it should respond, and any constraints on its behavior.
Creating a conversation thread provides the context container for the agent’s interactions. Threads maintain conversation history, enabling the agent to reference previous messages and maintain context across multiple turns. The Azure AI Agent Service manages thread storage, eliminating the need for custom state management code.
Interacting with the agent involves adding user messages to the thread and invoking the agent to generate responses. The agent processes the message, considers conversation history, and generates an appropriate response. Results stream back asynchronously, allowing for real-time response display.
Complete Python implementation demonstrates these concepts in a working example. The code creates an Azure AI Agent connection, defines a customer service agent, creates a conversation thread, processes a user query, displays the agent response, and properly cleans up resources by deleting the thread and agent after use. This cleanup prevents resource accumulation during development.
Running this code with python simple_agent.py demonstrates basic agent functionality. The agent receives the query, processes it using the configured model, and returns a helpful response based on its instructions. This foundational pattern extends to more complex scenarios including tool integration and multi-turn conversations.
Creating Your First Agent in C#
C# implementation follows similar patterns with language-specific syntax and conventions. Begin by creating a new console application or adding agent code to your existing project from Part 2.
Import required namespaces including Azure.Identity for authentication, Azure.AI.Projects for project client access, and Microsoft.SemanticKernel.Agents.AzureAI for Azure AI Agent integration. Configure your project endpoint and model deployment name from user secrets or environment variables established in Part 2.
The AzureAIAgent creation process in C# uses similar concepts to Python but with strongly-typed objects and async/await patterns. Create an AIProjectClient using the project endpoint and AzureCliCredential for authentication. Retrieve the AgentsClient from the project client to access agent operations.
Define the agent on the Azure AI Agent Service by calling CreateAgentAsync with the model deployment name, agent name, description, and instructions. This returns a PersistentAgent definition representing the server-side agent configuration. Wrap this definition in a Semantic Kernel AzureAIAgent instance to enable client-side agent operations.
Thread creation follows the same pattern as Python, calling CreateThreadAsync to establish a conversation context. Add user messages using the agent’s AddChatMessage method, then invoke GetResponse to generate the agent’s reply. The response includes both content and metadata about the agent’s processing.
Complete C# implementation shows a production-ready pattern including proper resource disposal using try-finally blocks or using statements. This ensures threads and agents are deleted even if exceptions occur during processing. Production code should implement robust error handling and logging beyond this simple example.
Running the C# implementation with dotnet run produces similar results to the Python version, demonstrating cross-language consistency in Semantic Kernel agent behavior. The underlying Azure AI Agent Service provides consistent functionality regardless of client language.
Creating Your First Agent in Node.js
Node.js and TypeScript implementations leverage the same Azure AI Foundry services with JavaScript-specific client libraries. Install the required packages as described in Part 2 including @azure/ai-projects and @azure/identity.
Create a new file named simple-agent.ts for TypeScript implementation. Import necessary types and classes from the Azure AI Projects SDK. Load environment configuration using dotenv at the application entry point.
The agent creation pattern in Node.js closely mirrors Python and C# implementations. Create an AIProjectClient instance with the project endpoint URL and DefaultAzureCredential. Access the agents property to get the AgentsClient for agent operations.
Agent definition uses createAgent method with configuration object specifying model deployment, name, description, and instructions. The Promise-based API works naturally with async/await syntax in modern JavaScript and TypeScript.
Thread creation and message handling follow familiar patterns. Create threads, add messages, and invoke the agent to generate responses. The JavaScript SDK provides the same capabilities as Python and C# with language-appropriate syntax and conventions.
TypeScript provides additional type safety benefits. Define interfaces for agent configuration, message types, and response structures. TypeScript compilation catches type errors during development, preventing runtime issues in production deployments.
Running the Node.js implementation demonstrates that JavaScript developers can build production-quality agents with the same capabilities as Python or C#. Language choice becomes a matter of team expertise and infrastructure preferences rather than feature availability.
Adding Plugins for External Capabilities
Real-world agents require access to external systems, data sources, and custom business logic beyond simple conversation. Plugins provide the mechanism for agents to execute custom code and integrate with existing systems.
Plugin development starts by creating a class that encapsulates related functionality. Each plugin contains one or more functions decorated with attributes that provide semantic descriptions. These descriptions enable the AI model to understand when and how to call each function.
In Python, plugins use the @kernel_function decorator to mark methods as callable by agents. The decorator includes a description parameter that explains the function’s purpose in natural language. Type hints on parameters and return values provide additional context for the AI model.
A weather plugin example demonstrates plugin patterns. The plugin class contains a get_current_weather function that accepts a city parameter and returns weather information. In a real implementation, this function would call a weather API. The example uses mock data to demonstrate the pattern without requiring API keys.
The function description explains that it provides current weather information for a specified city. Parameter annotations indicate the city parameter is a string representing the location. Return type annotation specifies that the function returns a string containing weather details.
Registering plugins with agents happens during agent creation. For AzureAIAgent in Python, pass a plugins list to the agent constructor containing instances of your plugin classes. The agent automatically discovers decorated functions and makes them available for invocation.
In C#, plugin registration uses the Kernel’s Plugins collection. The KernelPluginFactory.CreateFromType method creates a plugin from your plugin class. Add the plugin to the kernel before creating the agent. The agent inherits plugin access from its kernel instance.
C# plugins use the [KernelFunction] attribute to mark methods and the [Description] attribute to provide semantic descriptions. Parameter descriptions use similar attributes, creating a rich metadata model that AI models use for function selection.
JavaScript plugins follow similar patterns with decorators or explicit function registration. TypeScript provides type checking for plugin functions, ensuring parameter and return types match expected patterns.
Automatic Function Calling and Orchestration
Function calling represents one of Semantic Kernel’s most powerful capabilities. When an agent has plugins available, the AI model automatically determines when to invoke plugin functions based on user queries rather than requiring explicit function calls in code.
The function calling process operates through several steps orchestrated automatically by Semantic Kernel. First, the user submits a query to the agent. The AI model analyzes the query and available function descriptions to determine if any functions could help answer the query. If appropriate functions exist, the model generates a function call with extracted parameters from the user query.
Semantic Kernel receives the function call, validates the function name and parameters, and invokes the corresponding plugin method with extracted arguments. The function executes, accessing databases, calling APIs, or performing calculations as implemented. Results return to Semantic Kernel which forwards them to the AI model.
The AI model receives function results and generates a natural language response incorporating the data. This response returns to the user, completing the interaction. From the user’s perspective, they asked a question and received an answer. The function invocation happened transparently without requiring the user to know about underlying plugins.
Configuring automatic function calling requires setting FunctionChoiceBehavior on prompt execution settings. In Python, create AzureChatPromptExecutionSettings and set function_choice_behavior to FunctionChoiceBehavior.Auto(). This instructs the agent to automatically invoke functions when appropriate.
In C#, configure PromptExecutionSettings with FunctionChoiceBehavior set to FunctionChoiceBehavior.Auto(). Pass these settings through KernelArguments when creating the agent. The agent then handles function calling automatically during message processing.
Manual function calling remains available for scenarios requiring explicit control. Set auto_invoke to False in FunctionChoiceBehavior configuration. The model still identifies appropriate functions but returns function call information to your code rather than automatically executing them. Your code then decides whether to invoke the function, potentially adding validation, logging, or approval workflows.
Managing Conversation State and Context
Multi-turn conversations require maintaining state across interactions. AzureAIAgent handles this automatically through thread-based state management. Each thread represents a conversation context containing message history, function call results, and other contextual information.
Creating a thread establishes a conversation container. Add messages to the thread over time as users interact with the agent. The thread persists in Azure AI Agent Service storage, allowing conversations to span multiple sessions or even days for long-running processes.
Retrieving conversation history from a thread enables applications to display previous messages, implement conversation search, or analyze interaction patterns. The agent automatically considers thread history when generating responses, providing context-aware replies that reference previous exchanges.
Thread management best practices include creating separate threads for different conversations or users to prevent context mixing. Delete threads when conversations conclude to free resources and maintain privacy. Implement thread lifecycle management in production applications to handle long-running threads appropriately.
For ChatCompletionAgent, state management becomes the application’s responsibility. Maintain a message history array containing previous exchanges. Pass this history with each invocation so the agent considers prior context. This approach provides more control but requires explicit state management code.
Implementing Streaming Responses
Streaming responses improve user experience by displaying agent output as it generates rather than waiting for complete responses. This becomes particularly important for long or complex responses where users benefit from seeing progress.
Python streaming uses async iteration over response streams. Call the agent’s invoke method and iterate over returned items. Each item represents a piece of the response, potentially a text chunk, function call, or other content type. Display text chunks immediately as they arrive, providing real-time feedback.
C# streaming follows similar patterns with IAsyncEnumerable. The agent’s InvokeStreamingAsync method returns an async enumerable of response items. Use await foreach to iterate over items as they arrive. This pattern integrates naturally with ASP.NET Core response streaming for web applications.
JavaScript streaming uses async iterators or event emitters depending on SDK version and preferences. Modern JavaScript supports for-await-of syntax for consuming async iterables, providing clean streaming code patterns.
Streaming considerations include handling partial function calls where function parameters arrive incrementally, managing errors that occur mid-stream rather than before response starts, and implementing timeouts for streams that stop producing content. Production streaming implementations require robust error handling and user feedback for all edge cases.
Error Handling and Resilience Patterns
Production agent implementations require comprehensive error handling for various failure scenarios. Network issues can interrupt communication with Azure AI services. Model rate limits may throttle requests during high-volume periods. Invalid function calls can occur when models generate malformed parameters.
Python error handling uses try-except blocks around agent operations. Catch HttpResponseError for network and service errors. Implement retry logic with exponential backoff for transient failures. Log errors with sufficient context for debugging while avoiding sensitive data exposure.
C# exception handling uses try-catch blocks with specific exception types. Azure SDK exceptions provide detailed information about failure causes. Implement retry policies using Polly or similar resilience libraries for automatic retry with backoff. Consider circuit breaker patterns for sustained outages.
Timeout configuration prevents indefinite waits during network issues or slow model responses. Set appropriate timeouts on HTTP clients and agent invocations. Balance timeout duration against expected response times for complex queries requiring multiple function calls.
Fallback strategies provide graceful degradation when agent services are unavailable. Cache recent responses for frequently asked questions. Implement rule-based fallbacks for critical operations. Inform users clearly when operating in degraded mode rather than silently failing or providing incorrect information.
Testing and Debugging Agents
Testing agent behavior requires different approaches than traditional software testing due to AI model non-determinism. While you cannot guarantee exact responses, you can verify that agents handle expected scenarios correctly and fail gracefully on edge cases.
Unit testing plugins in isolation verifies business logic correctness. Mock external dependencies like database connections or API clients. Test plugin functions directly without involving AI models. This provides fast, deterministic tests for plugin implementation.
Integration testing with actual models verifies agent orchestration works correctly. Create test threads with known message sequences. Verify agents invoke expected plugins for specific queries. While exact response text varies, plugin invocation patterns should remain consistent.
Temperature settings affect response variability. Lower temperatures produce more consistent outputs, beneficial for testing. Set temperature to 0 or near 0 for maximum determinism during testing. Production deployments may use higher temperatures for more creative responses.
Logging provides insight into agent decision-making. Log all plugin invocations with parameters and results. Record model responses and conversation history for later analysis. Azure Application Insights integrates with Semantic Kernel to provide comprehensive telemetry.
Debugging locally uses VS Code debugging capabilities. Set breakpoints in plugin code to inspect execution. Step through Semantic Kernel orchestration to understand decision flow. The synchronous nature of function calls enables standard debugging techniques.
Performance Optimization Strategies
Agent performance impacts user experience and operational costs. Several strategies optimize both latency and token consumption.
Model selection significantly affects performance. Smaller models like GPT-4o-mini respond faster and cost less per request than larger models. Use GPT-4o-mini for routine queries and save GPT-4 for complex reasoning tasks requiring advanced capabilities.
Plugin design impacts execution time. Minimize external API calls within plugins. Batch database queries rather than executing multiple sequential queries. Cache frequently accessed data within plugin instances when appropriate.
Prompt engineering reduces token usage and improves response quality. Clear, concise instructions enable models to respond accurately with fewer tokens. Avoid repetitive or verbose instructions that consume tokens without improving outcomes.
Conversation history trimming prevents context windows from growing unbounded. Implement rolling windows that retain recent messages while discarding old exchanges. Summarize old conversation portions to maintain context in fewer tokens.
Parallel processing accelerates multi-agent scenarios. When multiple agents process independent tasks, execute them concurrently rather than sequentially. Async/await patterns in all three languages enable natural concurrency implementation.
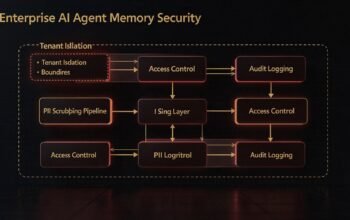
Security Considerations for Single Agents
Agent security requires careful attention to prevent unauthorized access, data leakage, and malicious plugin invocation.
Input validation prevents injection attacks where malicious users craft queries attempting to manipulate agent behavior. Validate and sanitize all user inputs before passing to agents. Implement content filtering to block inappropriate requests. Monitor for unusual query patterns suggesting attack attempts.
Plugin security requires careful review of code executed by agents. Validate all plugin inputs even when called by AI models. Implement least-privilege access for database connections and API credentials. Never allow plugins to execute arbitrary code from model responses.
Output validation prevents agents from exposing sensitive information. Implement content filters on agent responses. Redact personal information, credentials, or internal system details before returning responses to users. Log all agent outputs for security auditing.
Rate limiting prevents abuse and manages costs. Implement per-user limits on agent interactions. Track token consumption and alert on unusual patterns. Use Azure API Management or similar tools to enforce rate limits consistently.
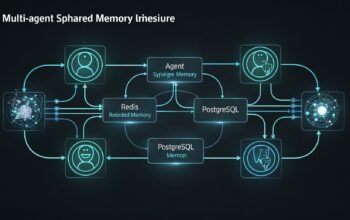
What’s Next: Multi-Agent Orchestration
Single agents provide powerful capabilities for many business automation scenarios. Part 4 of this series extends these concepts to multi-agent orchestration where specialized agents collaborate to solve complex problems.
Multi-agent systems enable divide-and-conquer approaches where each agent specializes in specific domains. A customer service workflow might use separate agents for order lookup, refund processing, and customer communication, with an orchestrator agent coordinating their collaboration.
The patterns and practices established in this article for single agents scale naturally to multi-agent scenarios. Plugin development, error handling, and state management remain important. Part 4 adds orchestration patterns including connected agents, Agent-to-Agent protocol, and multi-agent workflows.
References
- Microsoft Learn – Exploring the Semantic Kernel Azure AI Agent
- Semantic Kernel Blog – Using Azure AI Agents with Semantic Kernel in .NET and Python
- GitHub – Microsoft Semantic Kernel Repository
- Microsoft Learn – Plugins in Semantic Kernel
- Microsoft Learn – Configuring Agents with Semantic Kernel Plugins
- Visual Studio Magazine – Semantic Kernel + AutoGen = Open-Source Microsoft Agent Framework
- Microsoft Tech Community – Empowering Multi-Agent Solutions with Microsoft Agent Framework