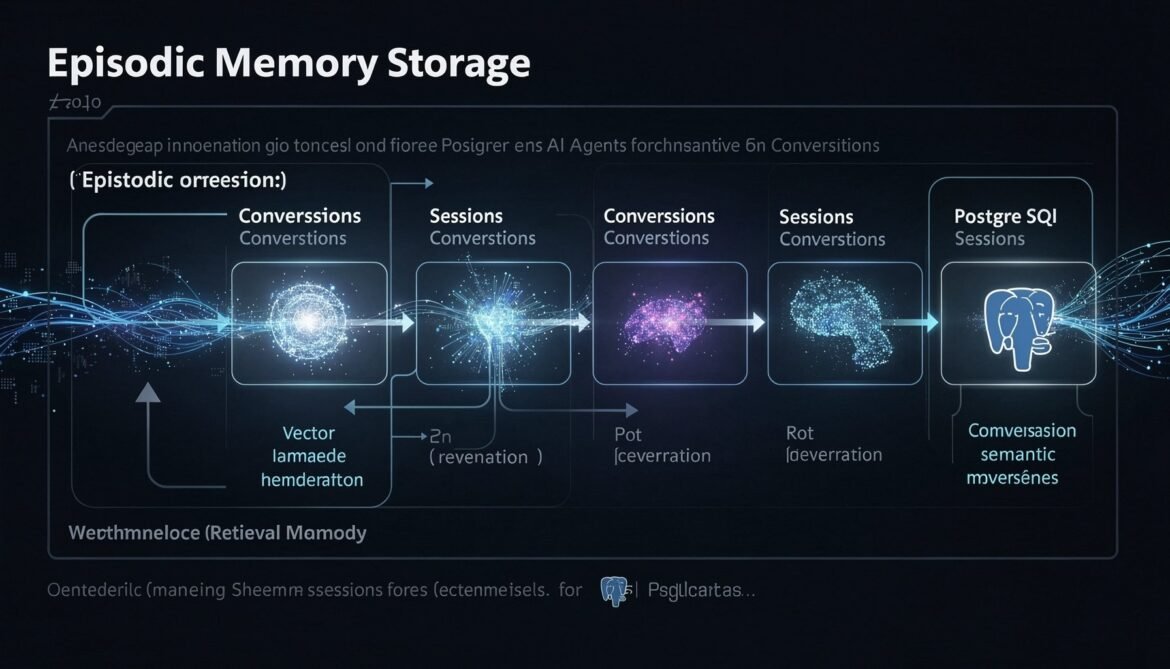
Part 1 of this series explained why single-session agents fail at enterprise scale and introduced the three memory types that solve it. This part builds the first and most foundational of those types: episodic memory. By the end of this post, you will have a working Node.js implementation that stores every conversation event, action, and outcome to PostgreSQL with pgvector, and retrieves the most relevant memories at the start of each new session.
What Episodic Memory Stores
Episodic memory is the record of specific events experienced by the agent over time. For a production agent, those events fall into three categories:
Conversation turns – Each user message and agent response, with timestamp, session ID, and user/tenant identifiers. This is the raw history of what was said and when.
Agent actions – Tool invocations, their inputs, outputs, and whether they succeeded or failed. An agent that called a database query tool, got a timeout, retried with a modified query, and succeeded on the second attempt should have all of that recorded, not just the final result.
Observations and outcomes – Higher-level events the agent records about its own reasoning: “User confirmed this approach is correct,” “This query pattern caused a timeout – use index hint next time,” “User’s preferred output format is JSON with camelCase keys.” These are the seeds of semantic and procedural memory but live in the episodic store at the point of creation.
Why PostgreSQL with pgvector
Episodic memory retrieval has two distinct patterns that need to work together. You need to retrieve by time (recent sessions are almost always relevant) and by semantic similarity (memories similar to the current query should surface even if they are old). PostgreSQL with pgvector handles both in a single system.
The alternative of using a dedicated vector database for semantic retrieval and a relational database for time-based retrieval creates synchronisation complexity and two query paths to maintain. PostgreSQL gives you SQL for structured time-based queries, pgvector for similarity search, JSONB for flexible metadata, and transactional writes for consistency, all in one system your operations team already knows how to run.
Database Schema
The schema needs to support both retrieval patterns efficiently while enforcing tenant isolation at the row level.
-- Enable pgvector extension
CREATE EXTENSION IF NOT EXISTS vector;
-- Sessions table: one row per agent session
CREATE TABLE agent_sessions (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
tenant_id TEXT NOT NULL,
user_id TEXT NOT NULL,
agent_id TEXT NOT NULL,
started_at TIMESTAMPTZ NOT NULL DEFAULT now(),
ended_at TIMESTAMPTZ,
metadata JSONB DEFAULT '{}'
);
CREATE INDEX idx_sessions_tenant_user
ON agent_sessions (tenant_id, user_id, started_at DESC);
-- Memory events table: one row per episodic event
CREATE TABLE episodic_memories (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
tenant_id TEXT NOT NULL,
user_id TEXT NOT NULL,
session_id UUID NOT NULL REFERENCES agent_sessions(id) ON DELETE CASCADE,
event_type TEXT NOT NULL, -- 'conversation_turn' | 'agent_action' | 'observation'
role TEXT, -- 'user' | 'assistant' | null for actions/observations
content TEXT NOT NULL, -- the raw text of the event
embedding vector(1536), -- OpenAI text-embedding-3-small dimension
importance FLOAT DEFAULT 0.5, -- 0.0 to 1.0, higher = more likely to retrieve
metadata JSONB DEFAULT '{}', -- tool name, action result, tags, etc.
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
-- Composite index for tenant-scoped time queries
CREATE INDEX idx_memories_tenant_user_time
ON episodic_memories (tenant_id, user_id, created_at DESC);
-- HNSW vector index for fast similarity search
-- HNSW is better than IVFFlat for recall at low latency
CREATE INDEX idx_memories_embedding
ON episodic_memories USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- Partial index for high-importance memories
CREATE INDEX idx_memories_important
ON episodic_memories (tenant_id, user_id, importance DESC)
WHERE importance > 0.7;erDiagram
agent_sessions {
UUID id PK
TEXT tenant_id
TEXT user_id
TEXT agent_id
TIMESTAMPTZ started_at
TIMESTAMPTZ ended_at
JSONB metadata
}
episodic_memories {
UUID id PK
TEXT tenant_id
TEXT user_id
UUID session_id FK
TEXT event_type
TEXT role
TEXT content
vector embedding
FLOAT importance
JSONB metadata
TIMESTAMPTZ created_at
}
agent_sessions ||--o{ episodic_memories : "contains"
Node.js Episodic Memory Client
The client handles session lifecycle, memory writes, and the two retrieval patterns. It uses the pg driver with a connection pool and calls the OpenAI embeddings API to generate vectors for similarity search.
// episodic-memory.js
import pg from 'pg';
import OpenAI from 'openai';
const { Pool } = pg;
const pool = new Pool({
connectionString: process.env.DATABASE_URL,
max: 20,
idleTimeoutMillis: 30000,
connectionTimeoutMillis: 5000,
});
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
// Generate embedding vector for a text string
async function embed(text) {
const response = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: text.slice(0, 8000), // truncate to stay within token limit
});
return response.data[0].embedding;
}
export class EpisodicMemoryClient {
constructor({ tenantId, userId, agentId }) {
this.tenantId = tenantId;
this.userId = userId;
this.agentId = agentId;
this.sessionId = null;
}
// Start a new session - call at the beginning of each agent run
async startSession(metadata = {}) {
const result = await pool.query(
`INSERT INTO agent_sessions (tenant_id, user_id, agent_id, metadata)
VALUES ($1, $2, $3, $4)
RETURNING id`,
[this.tenantId, this.userId, this.agentId, JSON.stringify(metadata)]
);
this.sessionId = result.rows[0].id;
return this.sessionId;
}
// Close the current session
async endSession() {
if (!this.sessionId) return;
await pool.query(
`UPDATE agent_sessions SET ended_at = now() WHERE id = $1`,
[this.sessionId]
);
this.sessionId = null;
}
// Write a memory event to the store
// Embedding is generated async and should not block the response path
async writeMemory({
eventType, // 'conversation_turn' | 'agent_action' | 'observation'
content,
role = null,
importance = 0.5,
metadata = {},
}) {
if (!this.sessionId) {
throw new Error('No active session. Call startSession() first.');
}
// Generate embedding - in production, queue this if latency is critical
const embedding = await embed(content);
const embeddingLiteral = `[${embedding.join(',')}]`;
await pool.query(
`INSERT INTO episodic_memories
(tenant_id, user_id, session_id, event_type, role, content, embedding, importance, metadata)
VALUES ($1, $2, $3, $4, $5, $6, $7::vector, $8, $9)`,
[
this.tenantId,
this.userId,
this.sessionId,
eventType,
role,
content,
embeddingLiteral,
importance,
JSON.stringify(metadata),
]
);
}
// Convenience method for conversation turns
async writeConversationTurn(role, content, importance = 0.5) {
return this.writeMemory({
eventType: 'conversation_turn',
role,
content,
importance,
});
}
// Convenience method for tool actions
async writeAgentAction({ toolName, input, output, success, importance = 0.6 }) {
const content = `Tool: ${toolName}\nInput: ${JSON.stringify(input)}\nOutput: ${JSON.stringify(output)}\nSuccess: ${success}`;
return this.writeMemory({
eventType: 'agent_action',
content,
importance,
metadata: { toolName, success },
});
}
// Convenience method for agent observations
async writeObservation(content, importance = 0.8) {
return this.writeMemory({
eventType: 'observation',
content,
importance,
});
}
// Retrieve recent memories (time-based)
async getRecentMemories({ limit = 20, eventTypes = null, sessionCount = 5 }) {
const typeFilter = eventTypes
? `AND event_type = ANY($4::text[])`
: '';
const result = await pool.query(
`SELECT em.id, em.event_type, em.role, em.content, em.importance,
em.metadata, em.created_at, s.started_at as session_started
FROM episodic_memories em
JOIN agent_sessions s ON em.session_id = s.id
WHERE em.tenant_id = $1
AND em.user_id = $2
AND s.id IN (
SELECT id FROM agent_sessions
WHERE tenant_id = $1 AND user_id = $2
ORDER BY started_at DESC
LIMIT $3
)
${typeFilter}
ORDER BY em.created_at DESC
LIMIT $${eventTypes ? 5 : 4}`,
eventTypes
? [this.tenantId, this.userId, sessionCount, eventTypes, limit]
: [this.tenantId, this.userId, sessionCount, limit]
);
return result.rows;
}
// Retrieve semantically similar memories (vector search)
async getSimilarMemories({ query, limit = 10, minImportance = 0.3, threshold = 0.75 }) {
const queryEmbedding = await embed(query);
const embeddingLiteral = `[${queryEmbedding.join(',')}]`;
const result = await pool.query(
`SELECT id, event_type, role, content, importance, metadata, created_at,
1 - (embedding <=> $3::vector) AS similarity
FROM episodic_memories
WHERE tenant_id = $1
AND user_id = $2
AND importance >= $5
AND 1 - (embedding <=> $3::vector) >= $6
ORDER BY embedding <=> $3::vector
LIMIT $4`,
[this.tenantId, this.userId, embeddingLiteral, limit, minImportance, threshold]
);
return result.rows;
}
// Hybrid retrieval: combine recency and similarity, deduplicated
async retrieveForContext({ query, recentLimit = 10, similarLimit = 10 }) {
const [recent, similar] = await Promise.all([
this.getRecentMemories({ limit: recentLimit }),
this.getSimilarMemories({ query, limit: similarLimit }),
]);
// Merge and deduplicate by id, prefer higher importance on conflict
const seen = new Map();
for (const m of [...recent, ...similar]) {
if (!seen.has(m.id) || m.importance > seen.get(m.id).importance) {
seen.set(m.id, m);
}
}
// Sort by created_at descending so context is chronological
return Array.from(seen.values())
.sort((a, b) => new Date(b.created_at) - new Date(a.created_at));
}
}Integrating Episodic Memory into an Agent Loop
The memory client integrates around the LLM call. At session start, retrieve relevant memories and inject them into the system prompt. After each turn, write the new events.
// agent.js
import Anthropic from '@anthropic-ai/sdk';
import { EpisodicMemoryClient } from './episodic-memory.js';
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
export class MemoryAwareAgent {
constructor({ tenantId, userId }) {
this.memory = new EpisodicMemoryClient({
tenantId,
userId,
agentId: 'production-agent-v1',
});
this.conversationHistory = [];
}
async startSession() {
await this.memory.startSession({ startedBy: 'user_request' });
}
async endSession() {
await this.memory.endSession();
this.conversationHistory = [];
}
// Format retrieved memories into a system prompt injection
formatMemoriesForContext(memories) {
if (!memories.length) return '';
const sections = {
observation: [],
conversation_turn: [],
agent_action: [],
};
for (const m of memories) {
sections[m.event_type]?.push(m);
}
let context = '\n\n--- Relevant memories from past sessions ---\n';
if (sections.observation.length) {
context += '\nKey observations about this user:\n';
context += sections.observation
.map(m => `- ${m.content}`)
.join('\n');
}
if (sections.conversation_turn.length) {
context += '\n\nRecent conversation history:\n';
context += sections.conversation_turn
.slice(0, 10) // cap to avoid context bloat
.map(m => `[${m.role}]: ${m.content}`)
.join('\n');
}
if (sections.agent_action.length) {
context += '\n\nRecent tool actions:\n';
context += sections.agent_action
.slice(0, 5)
.map(m => `- ${m.content}`)
.join('\n');
}
context += '\n--- End of memories ---\n';
return context;
}
async chat(userMessage) {
// Retrieve relevant memories for this query
const memories = await this.memory.retrieveForContext({
query: userMessage,
recentLimit: 10,
similarLimit: 8,
});
const memoryContext = this.formatMemoriesForContext(memories);
const systemPrompt = `You are a helpful production AI agent with access to long-term memory.
You remember past conversations and can build on prior context without the user needing to re-explain.
${memoryContext}`;
// Add user message to in-session history
this.conversationHistory.push({ role: 'user', content: userMessage });
// Call the LLM
const response = await anthropic.messages.create({
model: 'claude-sonnet-4-20250514',
max_tokens: 4096,
system: systemPrompt,
messages: this.conversationHistory,
});
const assistantMessage = response.content[0].text;
this.conversationHistory.push({ role: 'assistant', content: assistantMessage });
// Write memories async - do not await to avoid adding latency
Promise.all([
this.memory.writeConversationTurn('user', userMessage, 0.5),
this.memory.writeConversationTurn('assistant', assistantMessage, 0.5),
]).catch(err => console.error('Memory write failed:', err));
return assistantMessage;
}
// Call this when the agent makes a significant observation
async recordObservation(content, importance = 0.8) {
await this.memory.writeObservation(content, importance);
}
}sequenceDiagram
participant U as User
participant A as MemoryAwareAgent
participant M as EpisodicMemoryClient
participant DB as PostgreSQL + pgvector
participant LLM as Claude Sonnet 4.6
U->>A: chat("How is the auth refactor going?")
A->>M: retrieveForContext(query)
M->>DB: getRecentMemories (SQL time query)
M->>DB: getSimilarMemories (vector cosine search)
DB-->>M: merged memory rows
M-->>A: deduped, sorted memories
A->>A: formatMemoriesForContext()
A->>LLM: messages + system (with memory context)
LLM-->>A: assistant response
A-->>U: response
A->>M: writeConversationTurn(user) [async]
A->>M: writeConversationTurn(assistant) [async]
M->>DB: INSERT with embedding vector
Importance Scoring
Not all memories are equally worth retrieving. Importance scoring lets you bias retrieval toward high-value events. The default of 0.5 works for ordinary conversation turns. Here is a practical guide:
| Importance | Event type | Example |
|---|---|---|
| 0.9 – 1.0 | Critical observation | “User confirmed production deploy is blocked until security review passes” |
| 0.7 – 0.9 | Key preference or constraint | “User prefers TypeScript over JavaScript for all new services” |
| 0.6 – 0.7 | Successful tool result or action | “Database query pattern X returned results in under 50ms” |
| 0.4 – 0.6 | Ordinary conversation turns | Normal Q&A exchanges |
| 0.1 – 0.4 | Low-signal events | Greetings, confirmations, filler turns |
You can also have the LLM itself score importance. After generating a response, send the turn to a lightweight model with a prompt asking it to rate the importance of this exchange from 0 to 1 and return a JSON score. This adds a small async cost but produces better retrieval over time than static heuristics.
Async Write Queue for Production
The implementation above fires memory writes as a floating promise after each turn. This works but lacks durability: if the process crashes between the response and the write, the memory is lost. For production, route writes through a queue.
// memory-queue.js - Redis Streams writer for durable async memory writes
import { createClient } from 'redis';
const redis = createClient({ url: process.env.REDIS_URL });
await redis.connect();
export async function enqueueMemoryWrite(memoryEvent) {
await redis.xAdd('memory:write:queue', '*', {
payload: JSON.stringify(memoryEvent),
});
}
// memory-worker.js - runs as a separate process
import { createClient } from 'redis';
import { EpisodicMemoryClient } from './episodic-memory.js';
const redis = createClient({ url: process.env.REDIS_URL });
await redis.connect();
async function processMemoryWrites() {
while (true) {
const entries = await redis.xReadGroup(
'memory-workers',
`worker-${process.pid}`,
[{ key: 'memory:write:queue', id: '>' }],
{ COUNT: 10, BLOCK: 5000 }
);
if (!entries) continue;
for (const { messages } of entries) {
for (const { id, message } of messages) {
try {
const event = JSON.parse(message.payload);
const client = new EpisodicMemoryClient({
tenantId: event.tenantId,
userId: event.userId,
agentId: event.agentId,
});
// Reattach to existing session rather than starting a new one
client.sessionId = event.sessionId;
await client.writeMemory(event);
await redis.xAck('memory:write:queue', 'memory-workers', id);
} catch (err) {
console.error('Memory write failed:', err, 'message id:', id);
// Leave unacknowledged for retry via XAUTOCLAIM
}
}
}
}
}
processMemoryWrites();Pruning and Retention Policies
Episodic memory grows indefinitely without a retention policy. You need a strategy that keeps the high-value memories while pruning low-signal events that are no longer useful.
A practical default: retain all memories with importance above 0.7 indefinitely, retain all memories from the last 30 days regardless of importance, and delete memories older than 90 days with importance below 0.5. Run this as a nightly job.
// memory-pruner.js - run nightly via cron or Azure Functions timer
import pool from './db.js';
export async function pruneEpisodicMemories() {
const result = await pool.query(
`DELETE FROM episodic_memories
WHERE created_at < now() - INTERVAL '90 days'
AND importance < 0.5
RETURNING id`
);
console.log(`Pruned ${result.rowCount} low-importance episodic memories`);
return result.rowCount;
}What Is Next
Part 3 builds the semantic memory layer: the system that stores distilled facts and knowledge extracted from episodes, indexed for similarity search using Qdrant. Where episodic memory records what happened, semantic memory stores what the agent has learned, and retrieval is purely by conceptual similarity rather than by time.
References
- pgvector – “Open-Source Vector Similarity Search for PostgreSQL” (https://github.com/pgvector/pgvector)
- OpenAI – “Embeddings API Documentation” (https://platform.openai.com/docs/guides/embeddings)
- Anthropic – “Claude Sonnet 4.6 Tool Use Documentation” (https://docs.anthropic.com/en/docs/build-with-claude/tool-use)
- node-postgres – “pg Driver Documentation” (https://node-postgres.com/)
- Redis – “Redis Streams Documentation” (https://redis.io/docs/latest/develop/data-types/streams/)