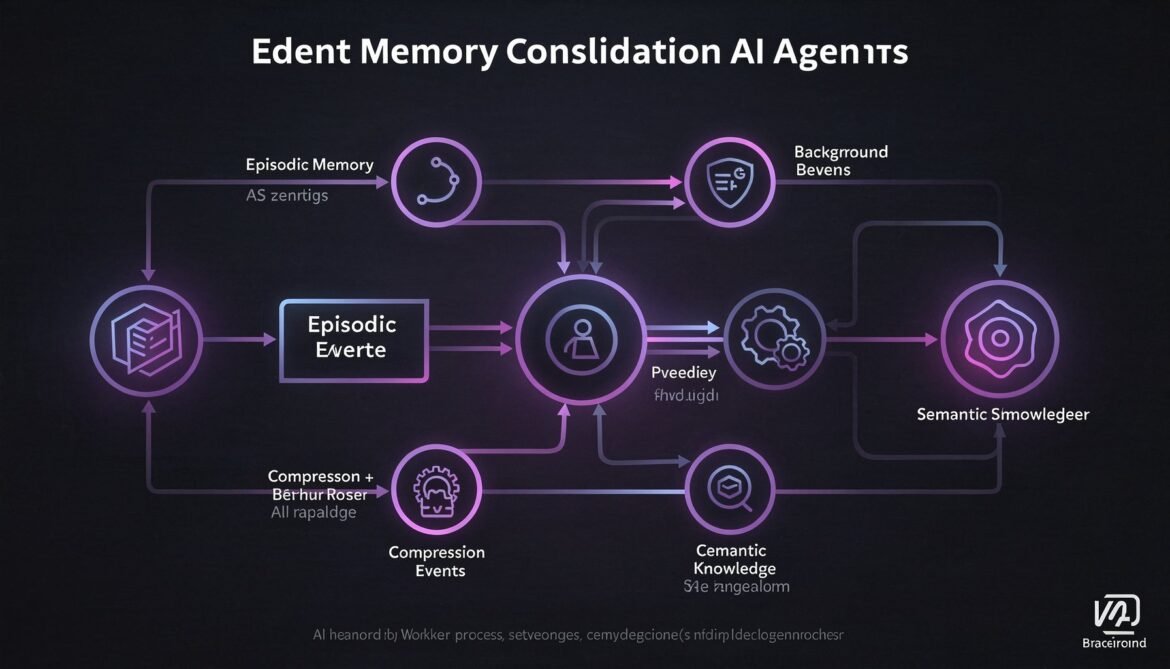
The episodic memory store built in Part 2 grows with every agent session. After weeks of use, a single user can accumulate thousands of conversation turns, tool results, and observations. Retrieving against that volume becomes slow, the injected context becomes noisy, and storage costs climb steadily. Memory consolidation solves this by running a background process that reads episodic events, extracts the durable knowledge they contain, writes it to semantic memory, and then prunes the raw events down to a manageable size.
This is closely analogous to how the human brain processes memory during sleep: converting recent experiences into long-term knowledge while discarding the low-signal details. For agents, it is the mechanism that prevents the system from becoming slower and noisier over time.
What Consolidation Does
Consolidation is a three-step pipeline that runs on a schedule for each active user:
Step 1: Read – Fetch episodic events older than a recency window (default: 48 hours) that have not yet been consolidated. These are the events safe to compress because they are unlikely to be needed verbatim in the next session.
Step 2: Extract and write to semantic memory – Send batches of episodic events to an LLM with a consolidation prompt that extracts durable facts, preferences, constraints, and patterns. Write the extracted facts to the semantic memory store built in Part 3.
Step 3: Prune – Mark consolidated episodic events as processed. Delete low-importance events beyond the retention window. Retain high-importance events (observations, critical decisions) indefinitely as an audit trail.
flowchart TD
subgraph Schedule["Consolidation Worker - runs every 6 hours"]
Trigger["Cron trigger\nor queue message"]
Users["Fetch active users\nwith unconsolidated events"]
Trigger --> Users
end
subgraph Pipeline["Per-User Consolidation Pipeline"]
Fetch["Fetch episodic events\nolder than 48h\nnot yet consolidated"]
Batch["Chunk into\nbatches of 30 events"]
LLM["LLM extraction\nclaude-haiku\nper batch"]
Write["Write facts\nto semantic store\nQdrant upsert"]
Mark["Mark episodic events\nas consolidated"]
Prune["Delete low-importance\nevents beyond\nretention window"]
Fetch --> Batch --> LLM --> Write --> Mark --> Prune
end
Users --> Pipeline
style Schedule fill:#1e3a5f,color:#fff
style Pipeline fill:#3b0764,color:#fff
Schema Addition: Consolidation Tracking
Add a consolidation status column to the episodic memories table from Part 2. This lets the worker query only unconsolidated events efficiently without a full table scan.
-- Add to episodic_memories table from Part 2
ALTER TABLE episodic_memories
ADD COLUMN consolidated BOOLEAN NOT NULL DEFAULT false,
ADD COLUMN consolidated_at TIMESTAMPTZ;
-- Index for the consolidation worker query
CREATE INDEX idx_memories_unconsolidated
ON episodic_memories (tenant_id, user_id, consolidated, created_at)
WHERE consolidated = false;Consolidation Worker
The worker runs as a standalone Node.js process. It pulls jobs from a Redis Stream so multiple worker instances can process different users in parallel without duplicating work.
// consolidation-worker.js
import pg from 'pg';
import Anthropic from '@anthropic-ai/sdk';
import { createClient } from 'redis';
import { SemanticMemoryClient } from './semantic-memory.js'; // Python client ported or HTTP wrapper
const { Pool } = pg;
const pool = new Pool({ connectionString: process.env.DATABASE_URL });
const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY });
const redis = createClient({ url: process.env.REDIS_URL });
await redis.connect();
const RECENCY_HOURS = 48; // only consolidate events older than this
const BATCH_SIZE = 30; // events per LLM extraction call
const RETENTION_DAYS = 90; // keep all events within this window
const LOW_IMPORTANCE = 0.5; // prune threshold beyond retention window
// --- LLM Extraction ---
const CONSOLIDATION_PROMPT = `You are a memory consolidation assistant for an AI agent.
You will receive a batch of raw episodic events (conversation turns, tool actions, observations).
Your job is to extract durable facts worth remembering long-term.
Extract only facts that are:
- Stable: will still be true in future sessions
- Specific: concrete preferences, constraints, entities, or patterns
- Non-trivial: not already obvious from context
Return a JSON array. Each object must have:
- category: "preference" | "constraint" | "domain_fact" | "entity" | "failure_pattern"
- subject: short label (e.g. "deploy_process", "code_style", "auth_service")
- fact: the fact as a single clear sentence
- confidence: float 0.0 to 1.0
Return only the JSON array, no other text. If nothing durable can be extracted, return [].
Events to analyse:
{events}`;
async function extractFacts(events) {
const eventText = events
.map(e => `[${e.event_type}] ${e.role ? e.role + ': ' : ''}${e.content}`)
.join('\n');
const response = await anthropic.messages.create({
model: 'claude-haiku-4-5-20251001',
max_tokens: 1024,
messages: [{
role: 'user',
content: CONSOLIDATION_PROMPT.replace('{events}', eventText),
}],
});
try {
const facts = JSON.parse(response.content[0].text.trim());
return Array.isArray(facts)
? facts.filter(f => f.confidence >= 0.6)
: [];
} catch {
return [];
}
}
// --- Episodic Event Fetching ---
async function fetchUnconsolidatedEvents(tenantId, userId, limit = 300) {
const cutoff = new Date(Date.now() - RECENCY_HOURS * 60 * 60 * 1000).toISOString();
const result = await pool.query(
`SELECT id, event_type, role, content, importance, created_at
FROM episodic_memories
WHERE tenant_id = $1
AND user_id = $2
AND consolidated = false
AND created_at < $3
ORDER BY created_at ASC
LIMIT $4`,
[tenantId, userId, cutoff, limit]
);
return result.rows;
}
// --- Mark Events as Consolidated ---
async function markConsolidated(eventIds) {
if (!eventIds.length) return;
await pool.query(
`UPDATE episodic_memories
SET consolidated = true, consolidated_at = now()
WHERE id = ANY($1::uuid[])`,
[eventIds]
);
}
// --- Prune Old Low-Importance Events ---
async function pruneOldEvents(tenantId, userId) {
const retentionCutoff = new Date(
Date.now() - RETENTION_DAYS * 24 * 60 * 60 * 1000
).toISOString();
const result = await pool.query(
`DELETE FROM episodic_memories
WHERE tenant_id = $1
AND user_id = $2
AND consolidated = true
AND created_at < $3
AND importance < $4
RETURNING id`,
[tenantId, userId, retentionCutoff, LOW_IMPORTANCE]
);
return result.rowCount;
}
// --- Per-User Consolidation ---
async function consolidateUser(tenantId, userId, sessionId) {
console.log(`[consolidation] Starting for user ${userId}`);
const events = await fetchUnconsolidatedEvents(tenantId, userId);
if (!events.length) {
console.log(`[consolidation] No events to consolidate for ${userId}`);
return { factsExtracted: 0, eventsPruned: 0 };
}
// Chunk events into batches
const batches = [];
for (let i = 0; i < events.length; i += BATCH_SIZE) {
batches.push(events.slice(i, i + BATCH_SIZE));
}
const semantic = new SemanticMemoryClient(tenantId, userId);
let totalFacts = 0;
for (const batch of batches) {
const facts = await extractFacts(batch);
if (facts.length) {
// Write each fact to semantic store via HTTP wrapper or direct Qdrant client
for (const fact of facts) {
await semantic.upsertFact({
category: fact.category,
subject: fact.subject,
fact: fact.fact,
confidence: fact.confidence,
sourceSessionId: sessionId,
});
}
totalFacts += facts.length;
}
// Mark this batch as consolidated regardless of fact count
await markConsolidated(batch.map(e => e.id));
}
// Prune old consolidated events beyond retention window
const pruned = await pruneOldEvents(tenantId, userId);
console.log(`[consolidation] ${userId}: extracted ${totalFacts} facts, pruned ${pruned} events`);
return { factsExtracted: totalFacts, eventsPruned: pruned };
}
// --- Redis Stream Worker Loop ---
async function runWorker() {
const workerName = `consolidation-worker-${process.pid}`;
// Ensure consumer group exists
try {
await redis.xGroupCreate('consolidation:jobs', 'consolidation-workers', '0', { MKSTREAM: true });
} catch (e) {
if (!e.message.includes('BUSYGROUP')) throw e;
}
console.log(`[worker] ${workerName} started`);
while (true) {
const entries = await redis.xReadGroup(
'consolidation-workers',
workerName,
[{ key: 'consolidation:jobs', id: '>' }],
{ COUNT: 5, BLOCK: 10000 }
);
if (!entries) continue;
for (const { messages } of entries) {
for (const { id: msgId, message } of messages) {
const { tenantId, userId, sessionId } = JSON.parse(message.payload);
try {
await consolidateUser(tenantId, userId, sessionId);
await redis.xAck('consolidation:jobs', 'consolidation-workers', msgId);
} catch (err) {
console.error(`[worker] Failed for ${userId}:`, err.message);
// Leave unacknowledged - XAUTOCLAIM will reassign after timeout
}
}
}
}
}
runWorker();Job Enqueuer: Triggering Consolidation After Sessions
Consolidation jobs are enqueued when an agent session ends. This ensures every active user gets consolidated on a rolling basis without requiring a full user scan.
// consolidation-enqueuer.js
import { createClient } from 'redis';
const redis = createClient({ url: process.env.REDIS_URL });
await redis.connect();
export async function enqueueConsolidation(tenantId, userId, sessionId) {
await redis.xAdd('consolidation:jobs', '*', {
payload: JSON.stringify({ tenantId, userId, sessionId }),
});
}
// Call this from your agent session teardown:
// await enqueueConsolidation(tenantId, userId, sessionId);Semantic Memory HTTP Wrapper for Node.js
The semantic memory client from Part 3 is in Python. The consolidation worker needs to write to it from Node.js. The cleanest approach is a small FastAPI service that wraps the Python client, giving you a language-agnostic HTTP interface.
# semantic_memory_api.py - FastAPI wrapper around the Qdrant semantic client
from fastapi import FastAPI
from pydantic import BaseModel
from semantic_memory import SemanticMemoryClient
app = FastAPI()
class UpsertRequest(BaseModel):
tenant_id: str
user_id: str
category: str
subject: str
fact: str
confidence: float
source_session_id: str
@app.post("/upsert")
async def upsert_fact(req: UpsertRequest):
client = SemanticMemoryClient(req.tenant_id, req.user_id)
stored = client.store_single_fact(
category=req.category,
subject=req.subject,
fact=req.fact,
confidence=req.confidence,
source_session_id=req.source_session_id,
)
return {"stored": stored}
@app.get("/retrieve")
async def retrieve(tenant_id: str, user_id: str, query: str, top_k: int = 10):
client = SemanticMemoryClient(tenant_id, user_id)
results = client.retrieve(query=query, top_k=top_k)
return {"results": results}
# Run with: uvicorn semantic_memory_api:app --port 8001// semantic-memory-client.js - Node.js HTTP client for the Python semantic API
export class SemanticMemoryClient {
constructor(tenantId, userId) {
this.tenantId = tenantId;
this.userId = userId;
this.baseUrl = process.env.SEMANTIC_MEMORY_API_URL || 'http://localhost:8001';
}
async upsertFact({ category, subject, fact, confidence, sourceSessionId }) {
const res = await fetch(`${this.baseUrl}/upsert`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
tenant_id: this.tenantId,
user_id: this.userId,
category,
subject,
fact,
confidence,
source_session_id: sourceSessionId,
}),
});
if (!res.ok) throw new Error(`Semantic upsert failed: ${res.status}`);
return res.json();
}
async retrieve(query, topK = 10) {
const params = new URLSearchParams({
tenant_id: this.tenantId,
user_id: this.userId,
query,
top_k: topK,
});
const res = await fetch(`${this.baseUrl}/retrieve?${params}`);
if (!res.ok) throw new Error(`Semantic retrieve failed: ${res.status}`);
const data = await res.json();
return data.results;
}
}sequenceDiagram
participant AS as Agent Session
participant RQ as Redis Stream\nconsolidation:jobs
participant CW as Consolidation Worker\n(Node.js)
participant DB as PostgreSQL\n(episodic_memories)
participant LLM as Claude Haiku
participant SA as Semantic API\n(Python FastAPI)
participant QD as Qdrant
AS->>RQ: enqueueConsolidation(tenantId, userId, sessionId)
CW->>RQ: xReadGroup - claim job
CW->>DB: fetch unconsolidated events older than 48h
DB-->>CW: batch of 30 events
CW->>LLM: extractFacts(batch)
LLM-->>CW: JSON fact array
CW->>SA: POST /upsert per fact
SA->>QD: upsert by stable ID
CW->>DB: markConsolidated(event IDs)
CW->>DB: pruneOldEvents(beyond retention)
CW->>RQ: xAck - job complete
Handling XAUTOCLAIM for Failed Jobs
If a worker crashes mid-consolidation, its claimed messages stay unacknowledged. Redis XAUTOCLAIM reassigns them to another worker after a timeout. Add this to your worker startup to reclaim stale jobs.
// Add to runWorker() before the main loop
async function reclaimStalledJobs(workerName) {
const staleMs = 5 * 60 * 1000; // reclaim jobs idle for over 5 minutes
const { messages } = await redis.xAutoClaim(
'consolidation:jobs',
'consolidation-workers',
workerName,
staleMs,
'0-0',
{ COUNT: 10 }
);
if (messages.length) {
console.log(`[worker] Reclaimed ${messages.length} stalled jobs`);
}
return messages;
}Consolidation Metrics to Track
| Metric | What it tells you | Alert threshold |
|---|---|---|
| consolidation_lag_hours | How far behind the worker is per user | Alert if > 24h |
| facts_per_batch | Extraction quality – should be 2-8 per batch | Investigate if consistently 0 |
| queue_depth | Backlog of consolidation jobs | Alert if > 500 |
| prune_rate | Events pruned per run – confirms retention policy is active | Alert if 0 for 7 days |
| semantic_store_size | Total facts per user – should grow slowly | Investigate if > 10,000 per user |
Tuning the Consolidation Window
The 48-hour recency window is a starting point. Tune it based on your agent’s session cadence. If users interact multiple times per day, a shorter window (12-24 hours) keeps semantic memory fresher. If users interact weekly, a longer window (72+ hours) avoids consolidating sessions that the user might return to imminently. The key constraint is that you should never consolidate events from the current or most recent session, as the agent may still need them verbatim.
What Is Next
Part 6 builds multi-agent shared memory: the architecture that lets separate agent instances share episodic and semantic memory across a network, using Redis for low-latency shared state and PostgreSQL for durable cross-agent event history. This is the foundation for collaborative agent systems where multiple specialised agents work on the same user’s problems.
References
- Redis – “Redis Streams Documentation” (https://redis.io/docs/latest/develop/data-types/streams/)
- Anthropic – “Claude Models Overview including claude-haiku” (https://docs.anthropic.com/en/docs/about-claude/models/overview)
- FastAPI – “FastAPI Documentation” (https://fastapi.tiangolo.com/)
- pgvector – “Open-Source Vector Similarity Search for PostgreSQL” (https://github.com/pgvector/pgvector)
- Qdrant – “Vector Database Documentation” (https://qdrant.tech/documentation/)