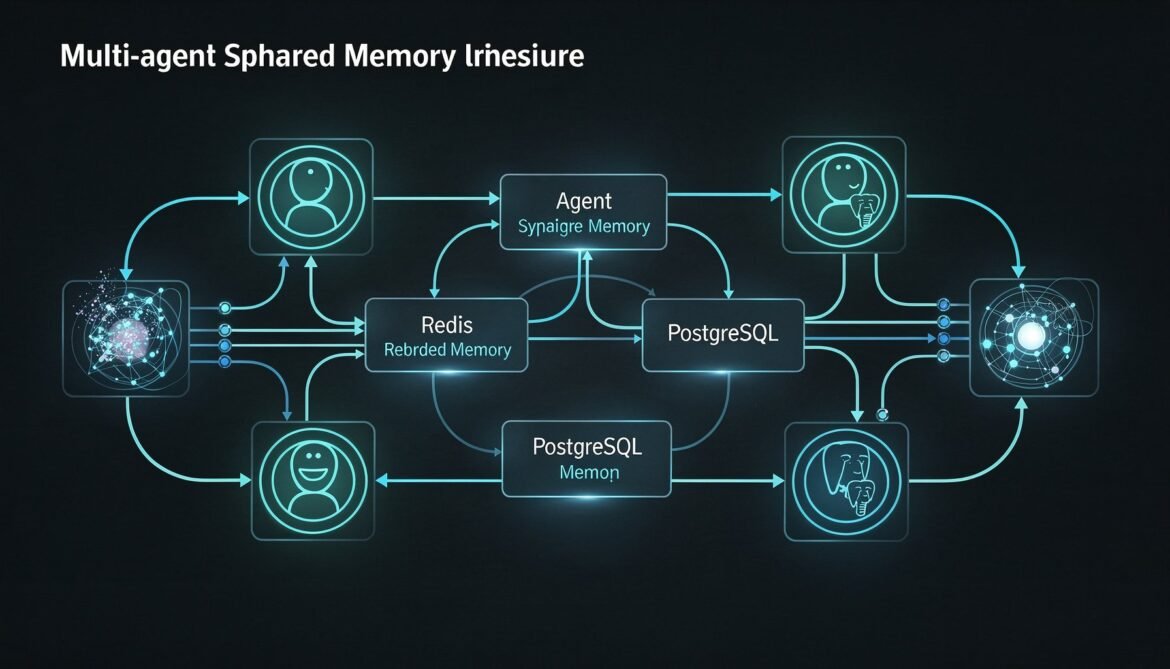
Every part of this series so far has treated memory as belonging to a single agent. One agent, one episodic store, one semantic store, one procedural store. That model covers a lot of ground, but enterprise AI systems increasingly deploy fleets of specialised agents that collaborate on the same user’s problems. A research agent, a code agent, a deployment agent, and a review agent might all work on the same project. If each operates in its own memory silo, they duplicate effort, contradict each other, and lose the compound benefit of shared experience.
This part builds shared memory: the layer that lets multiple agent instances read and write to the same memory spaces, coordinate without conflicts, and accumulate collective knowledge about a user or project. The implementation uses Redis for low-latency shared state and pub/sub coordination, and PostgreSQL for durable cross-agent episodic history. Everything is in Python.
Two Modes of Multi-Agent Memory
Before writing any code, it is worth being precise about what “shared memory” means in a multi-agent context, because there are two distinct patterns with different requirements.
Shared user memory – Multiple agents serving the same user share that user’s memory stores. A research agent and a code agent both write to and read from the same episodic and semantic memory for user-123. They each contribute their specialised observations, and both benefit from what the other has learned. This is the most common pattern and the one this part focuses on.
Shared workspace memory – Multiple agents collaborating on a specific task (a “project” or “workspace”) share a memory space scoped to that task rather than to any individual user. An orchestrator agent, a sub-agent, and a reviewer agent all read and write to the same workspace context. This is the right model for hierarchical agent systems where a coordinator spawns workers.
This part implements both, with a clean abstraction that makes switching between them a configuration change rather than a code change.
flowchart TD
subgraph UserMemory["Shared User Memory"]
RA["Research Agent"]
CA["Code Agent"]
DA["Deploy Agent"]
UM[("User Memory\ntenant_id + user_id scope")]
RA -->|read/write| UM
CA -->|read/write| UM
DA -->|read/write| UM
end
subgraph WorkspaceMemory["Shared Workspace Memory"]
OA["Orchestrator Agent"]
SA1["Sub-Agent 1"]
SA2["Sub-Agent 2"]
WM[("Workspace Memory\ntenant_id + workspace_id scope")]
OA -->|read/write| WM
SA1 -->|read/write| WM
SA2 -->|read/write| WM
end
Redis[("Redis\nLow-latency coordination\nPub/Sub + short-TTL cache")]
PG[("PostgreSQL\nDurable event history\ncross-agent episodic log")]
UM & WM --> Redis & PG
style UserMemory fill:#1e3a5f,color:#fff
style WorkspaceMemory fill:#166534,color:#fff
Schema: Cross-Agent Episodic Log
The episodic table from Part 2 is user-scoped. For multi-agent memory we need a scope field that can be either a user ID or a workspace ID, plus an agent identifier so you can see which agent wrote each event.
-- Cross-agent episodic memory table
-- Extends the Part 2 schema with scope and agent_id columns
CREATE TABLE shared_episodic_memories (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
tenant_id TEXT NOT NULL,
-- Scope: either user-scoped or workspace-scoped
scope_type TEXT NOT NULL, -- 'user' | 'workspace'
scope_id TEXT NOT NULL, -- user_id or workspace_id
-- Which agent wrote this event
agent_id TEXT NOT NULL,
agent_type TEXT NOT NULL, -- 'research' | 'code' | 'deploy' | 'orchestrator' etc.
-- Event content (same as Part 2)
event_type TEXT NOT NULL,
role TEXT,
content TEXT NOT NULL,
embedding vector(1536),
importance FLOAT DEFAULT 0.5,
metadata JSONB DEFAULT '{}',
-- Consolidation tracking
consolidated BOOLEAN NOT NULL DEFAULT false,
consolidated_at TIMESTAMPTZ,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
CREATE INDEX idx_shared_ep_scope
ON shared_episodic_memories (tenant_id, scope_type, scope_id, created_at DESC);
CREATE INDEX idx_shared_ep_agent
ON shared_episodic_memories (tenant_id, scope_type, scope_id, agent_id, created_at DESC);
CREATE INDEX idx_shared_ep_embedding
ON shared_episodic_memories USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
CREATE INDEX idx_shared_ep_unconsolidated
ON shared_episodic_memories (tenant_id, scope_type, scope_id, consolidated)
WHERE consolidated = false;Redis Layer: Coordination and Short-TTL Cache
Redis serves two roles in the shared memory architecture. First, it acts as a low-latency cache for the most recent events in a shared scope, avoiding a PostgreSQL round-trip for agents that need the last N events from a workspace. Second, it provides pub/sub for memory event notifications so agents can react to what other agents write without polling.
# shared_memory_redis.py
import json
import asyncio
from datetime import datetime, timezone
from typing import Callable
import redis.asyncio as aioredis
RECENT_EVENTS_TTL = 3600 # cache recent events for 1 hour
MAX_CACHED_EVENTS = 100 # max events kept in Redis per scope
class SharedMemoryRedis:
"""
Redis layer for multi-agent memory coordination.
Handles recent event caching and cross-agent pub/sub notifications.
"""
def __init__(self, redis_url: str):
self.redis = aioredis.from_url(redis_url, decode_responses=True)
def _scope_key(self, tenant_id: str, scope_type: str, scope_id: str) -> str:
return f"mem:{tenant_id}:{scope_type}:{scope_id}"
def _channel(self, tenant_id: str, scope_type: str, scope_id: str) -> str:
return f"mem_events:{tenant_id}:{scope_type}:{scope_id}"
async def push_event(
self,
tenant_id: str,
scope_type: str,
scope_id: str,
agent_id: str,
event_type: str,
content: str,
importance: float = 0.5,
metadata: dict | None = None,
) -> None:
key = self._scope_key(tenant_id, scope_type, scope_id)
channel = self._channel(tenant_id, scope_type, scope_id)
event = {
"agent_id": agent_id,
"event_type": event_type,
"content": content,
"importance": importance,
"metadata": metadata or {},
"created_at": datetime.now(timezone.utc).isoformat(),
}
serialized = json.dumps(event)
pipe = self.redis.pipeline()
# Push to left of list (newest first)
pipe.lpush(key, serialized)
# Trim to max cached events
pipe.ltrim(key, 0, MAX_CACHED_EVENTS - 1)
# Reset TTL
pipe.expire(key, RECENT_EVENTS_TTL)
# Publish notification to other agents
pipe.publish(channel, serialized)
await pipe.execute()
async def get_recent_events(
self,
tenant_id: str,
scope_type: str,
scope_id: str,
limit: int = 20,
) -> list[dict]:
key = self._scope_key(tenant_id, scope_type, scope_id)
raw = await self.redis.lrange(key, 0, limit - 1)
return [json.loads(r) for r in raw]
async def subscribe_to_scope(
self,
tenant_id: str,
scope_type: str,
scope_id: str,
handler: Callable[[dict], None],
) -> None:
"""Subscribe to memory events for a scope. Calls handler for each new event."""
channel = self._channel(tenant_id, scope_type, scope_id)
pubsub = self.redis.pubsub()
await pubsub.subscribe(channel)
async for message in pubsub.listen():
if message["type"] == "message":
event = json.loads(message["data"])
await handler(event)
async def set_workspace_context(
self,
tenant_id: str,
workspace_id: str,
context: dict,
ttl: int = 7200,
) -> None:
"""Store structured workspace context (task description, agent roster, status)."""
key = f"workspace_ctx:{tenant_id}:{workspace_id}"
await self.redis.setex(key, ttl, json.dumps(context))
async def get_workspace_context(
self,
tenant_id: str,
workspace_id: str,
) -> dict | None:
key = f"workspace_ctx:{tenant_id}:{workspace_id}"
raw = await self.redis.get(key)
return json.loads(raw) if raw else NoneShared Memory Client
The shared memory client wraps both the Redis layer and PostgreSQL writes into a single interface that agents use regardless of whether they are operating in user-scoped or workspace-scoped mode.
# shared_memory_client.py
import asyncpg
from openai import AsyncOpenAI
from shared_memory_redis import SharedMemoryRedis
oai = AsyncOpenAI()
async def embed(text: str) -> list[float]:
response = await oai.embeddings.create(
model="text-embedding-3-small",
input=text[:8000],
)
return response.data[0].embedding
class SharedMemoryClient:
"""
Unified interface for multi-agent shared memory.
Works for both user-scoped and workspace-scoped memory.
"""
def __init__(
self,
tenant_id: str,
scope_type: str, # 'user' or 'workspace'
scope_id: str, # user_id or workspace_id
agent_id: str,
agent_type: str,
db_pool: asyncpg.Pool,
redis: SharedMemoryRedis,
):
self.tenant_id = tenant_id
self.scope_type = scope_type
self.scope_id = scope_id
self.agent_id = agent_id
self.agent_type = agent_type
self.db = db_pool
self.redis = redis
async def write_event(
self,
event_type: str,
content: str,
role: str | None = None,
importance: float = 0.5,
metadata: dict | None = None,
) -> None:
"""Write an event to both Redis (fast, short-lived) and PostgreSQL (durable)."""
vector = await embed(content)
embedding_literal = f"[{','.join(str(v) for v in vector)}]"
# Write to PostgreSQL for durability
await self.db.execute(
"""
INSERT INTO shared_episodic_memories
(tenant_id, scope_type, scope_id, agent_id, agent_type,
event_type, role, content, embedding, importance, metadata)
VALUES ($1, $2, $3, $4, $5, $6, $7, $8, $9::vector, $10, $11)
""",
self.tenant_id, self.scope_type, self.scope_id,
self.agent_id, self.agent_type,
event_type, role, content, embedding_literal,
importance, metadata or {},
)
# Push to Redis for low-latency cross-agent access
await self.redis.push_event(
tenant_id=self.tenant_id,
scope_type=self.scope_type,
scope_id=self.scope_id,
agent_id=self.agent_id,
event_type=event_type,
content=content,
importance=importance,
metadata=metadata or {},
)
async def get_recent_shared(self, limit: int = 20) -> list[dict]:
"""Get recent events from all agents in this scope (Redis-backed, fast)."""
return await self.redis.get_recent_events(
self.tenant_id, self.scope_type, self.scope_id, limit
)
async def search_shared(self, query: str, limit: int = 10, min_similarity: float = 0.72) -> list[dict]:
"""Semantic search across all agents' events in this scope (PostgreSQL + pgvector)."""
vector = await embed(query)
embedding_literal = f"[{','.join(str(v) for v in vector)}]"
rows = await self.db.fetch(
"""
SELECT agent_id, agent_type, event_type, role, content,
importance, metadata, created_at,
1 - (embedding <=> $1::vector) AS similarity
FROM shared_episodic_memories
WHERE tenant_id = $2
AND scope_type = $3
AND scope_id = $4
AND 1 - (embedding <=> $1::vector) >= $5
ORDER BY embedding <=> $1::vector
LIMIT $6
""",
embedding_literal, self.tenant_id,
self.scope_type, self.scope_id,
min_similarity, limit,
)
return [dict(r) for r in rows]
async def get_agent_history(self, target_agent_id: str, limit: int = 30) -> list[dict]:
"""Get recent events written by a specific agent in this scope."""
rows = await self.db.fetch(
"""
SELECT event_type, role, content, importance, metadata, created_at
FROM shared_episodic_memories
WHERE tenant_id = $1
AND scope_type = $2
AND scope_id = $3
AND agent_id = $4
ORDER BY created_at DESC
LIMIT $5
""",
self.tenant_id, self.scope_type, self.scope_id, target_agent_id, limit,
)
return [dict(r) for r in rows]
def format_shared_context(self, events: list[dict], max_events: int = 15) -> str:
if not events:
return ""
lines = ["\n--- Shared memory from collaborating agents ---"]
for e in events[:max_events]:
agent = e.get("agent_id", "unknown")
content = e.get("content", "")
lines.append(f"[{agent}]: {content}")
lines.append("--- End of shared memory ---\n")
return "\n".join(lines)sequenceDiagram
participant RA as Research Agent
participant CA as Code Agent
participant SM as SharedMemoryClient
participant RD as Redis\n(recent events cache)
participant PG as PostgreSQL\n(durable log)
RA->>SM: write_event("observation", "Auth service uses OAuth2 PKCE flow")
SM->>PG: INSERT into shared_episodic_memories
SM->>RD: lpush + publish to channel
Note over CA: CA starts working on auth-related task
CA->>SM: get_recent_shared(limit=20)
SM->>RD: lrange (fast, no DB hit)
RD-->>CA: [Research Agent: "Auth service uses OAuth2 PKCE flow", ...]
CA->>SM: search_shared("OAuth token validation pattern")
SM->>PG: vector similarity search
PG-->>CA: relevant cross-agent events
CA->>SM: write_event("observation", "Token validation must use RS256 not HS256")
SM->>PG: INSERT
SM->>RD: lpush + publish
Note over RA: RA receives pub/sub notification\nand updates its working context
Workspace Orchestrator Pattern
For hierarchical agent systems, the orchestrator creates and owns the workspace, initialises its context in Redis, and coordinates sub-agent access. Sub-agents read the workspace context at startup and write their outputs back to the shared scope.
# orchestrator.py
import uuid
import asyncpg
from shared_memory_redis import SharedMemoryRedis
from shared_memory_client import SharedMemoryClient
class OrchestratorAgent:
def __init__(self, tenant_id: str, db_pool: asyncpg.Pool, redis: SharedMemoryRedis):
self.tenant_id = tenant_id
self.db = db_pool
self.redis = redis
async def create_workspace(self, task_description: str, agent_roster: list[str]) -> str:
workspace_id = str(uuid.uuid4())
context = {
"workspace_id": workspace_id,
"task": task_description,
"agents": agent_roster,
"status": "active",
"created_at": __import__("datetime").datetime.utcnow().isoformat(),
}
# Store workspace context in Redis for fast agent lookup
await self.redis.set_workspace_context(
self.tenant_id, workspace_id, context
)
# Write initial event to durable store
mem = SharedMemoryClient(
tenant_id=self.tenant_id,
scope_type="workspace",
scope_id=workspace_id,
agent_id="orchestrator",
agent_type="orchestrator",
db_pool=self.db,
redis=self.redis,
)
await mem.write_event(
event_type="workspace_created",
content=f"Workspace created for task: {task_description}. Agents: {', '.join(agent_roster)}",
importance=0.9,
)
return workspace_id
async def get_workspace_summary(self, workspace_id: str) -> dict:
"""Pull all events from the workspace for a final summary."""
mem = SharedMemoryClient(
tenant_id=self.tenant_id,
scope_type="workspace",
scope_id=workspace_id,
agent_id="orchestrator",
agent_type="orchestrator",
db_pool=self.db,
redis=self.redis,
)
recent = await mem.get_recent_shared(limit=50)
context = await self.redis.get_workspace_context(self.tenant_id, workspace_id)
return {
"context": context,
"recent_events": recent,
"event_count": len(recent),
}
class SubAgent:
"""Template for a sub-agent that participates in a workspace."""
def __init__(
self,
tenant_id: str,
workspace_id: str,
agent_id: str,
agent_type: str,
db_pool: asyncpg.Pool,
redis: SharedMemoryRedis,
):
self.mem = SharedMemoryClient(
tenant_id=tenant_id,
scope_type="workspace",
scope_id=workspace_id,
agent_id=agent_id,
agent_type=agent_type,
db_pool=db_pool,
redis=redis,
)
self.redis = redis
self.tenant_id = tenant_id
self.workspace_id = workspace_id
async def get_task_context(self) -> str:
"""Assemble context from shared workspace memory at task start."""
recent = await self.mem.get_recent_shared(limit=20)
ctx = await self.redis.get_workspace_context(self.tenant_id, self.workspace_id)
lines = [f"Workspace task: {ctx['task'] if ctx else 'unknown'}"]
lines.append(self.mem.format_shared_context(recent))
return "\n".join(lines)
async def publish_result(self, result: str, importance: float = 0.8) -> None:
"""Write agent output back to shared workspace memory."""
await self.mem.write_event(
event_type="agent_result",
content=result,
importance=importance,
)Write Conflict Prevention
When multiple agents write to the same scope concurrently, the main risk is not data corruption (PostgreSQL handles that with ACID guarantees) but semantic duplication: two agents writing nearly identical observations within seconds of each other. Handle this with a short deduplication window in Redis.
import hashlib
async def write_event_deduped(
self,
event_type: str,
content: str,
dedup_window_seconds: int = 30,
**kwargs,
) -> bool:
"""
Write event only if no identical content was written in the last N seconds.
Returns True if written, False if deduplicated.
"""
content_hash = hashlib.sha256(
f"{self.scope_id}:{content}".encode()
).hexdigest()[:16]
dedup_key = f"mem_dedup:{self.tenant_id}:{self.scope_id}:{content_hash}"
# SET NX with TTL - only succeeds if key does not exist
written = await self.redis.redis.set(
dedup_key, "1", nx=True, ex=dedup_window_seconds
)
if not written:
return False # duplicate within window, skip
await self.write_event(event_type=event_type, content=content, **kwargs)
return TrueCross-Agent Semantic Memory
The semantic memory layer from Part 3 (Qdrant) can be extended to support shared scopes with a single field addition. The scope_id payload field replaces the user_id field when operating in workspace mode, and the retrieval filter switches accordingly. No structural changes to the Qdrant collection are needed.
# Extension to SemanticMemoryClient from Part 3
# Add scope_type and scope_id parameters to support workspace scoping
def retrieve_shared(
self,
query: str,
scope_type: str,
scope_id: str,
top_k: int = 10,
) -> list[dict]:
query_vector = embed_sync(query)
# Filter by scope instead of individual user
must_conditions = [
FieldCondition(key="tenant_id", match=MatchValue(value=self.tenant_id)),
FieldCondition(key="scope_type", match=MatchValue(value=scope_type)),
FieldCondition(key="scope_id", match=MatchValue(value=scope_id)),
]
results = qdrant.search(
collection_name=COLLECTION,
query_vector=query_vector,
query_filter=Filter(must=must_conditions),
limit=top_k,
score_threshold=0.72,
with_payload=True,
)
return [{"fact": r.payload["fact"], "similarity": r.score} for r in results]flowchart LR
subgraph Agents["Agent Fleet"]
OA["Orchestrator\norchestrator"]
RA["Research Agent\nresearch"]
CA["Code Agent\ncode"]
REV["Review Agent\nreview"]
end
subgraph SharedMem["Shared Memory Layer"]
RC[("Redis\nRecent events\nPub/Sub\nWorkspace context\nDedup keys")]
PG[("PostgreSQL\nDurable episodic log\nVector search\nAll agent events")]
QD[("Qdrant\nShared semantic facts\nscoped by workspace_id")]
end
OA -->|create workspace| RC
OA & RA & CA & REV -->|write_event| PG
OA & RA & CA & REV -->|push + publish| RC
RC -->|notify on new event| OA & RA & CA & REV
RA -->|store facts| QD
CA -->|retrieve facts| QD
style Agents fill:#1e3a5f,color:#fff
style SharedMem fill:#166534,color:#fff
Practical Limits and Guardrails
Shared memory introduces coordination overhead that solo-agent memory does not have. A few guardrails keep the system from becoming a bottleneck.
| Risk | Guardrail |
|---|---|
| Context bloat from too many agents writing | Cap get_recent_shared at 20-30 events in context injection. Use search_shared for targeted retrieval beyond that. |
| Noisy events from low-quality sub-agents | Filter by importance >= 0.6 in shared context reads. Only high-importance events cross agent boundaries. |
| Cross-tenant data leakage | Always enforce tenant_id in every query. Never pass scope_id without tenant_id. Test with a two-tenant fixture in CI. |
| Redis memory growth | Set MAX_CACHED_EVENTS and RECENT_EVENTS_TTL conservatively. Redis is a cache, not a source of truth. |
| Pub/sub fan-out at scale | Use channel-per-scope to avoid broadcasting to unrelated agents. Unsubscribe inactive agents promptly. |
What Is Next
Part 7 covers the security layer: tenant isolation at the storage level, PII scrubbing before events are written, access control for shared scopes, and audit logging. This is the layer that makes shared memory safe to run in regulated enterprise environments where data residency and privacy compliance are mandatory requirements.
References
- Redis – “Pub/Sub Documentation” (https://redis.io/docs/latest/develop/interact/pubsub/)
- asyncpg – “PostgreSQL Async Driver for Python” (https://magicstack.github.io/asyncpg/current/)
- Qdrant – “Payload Filtering Documentation” (https://qdrant.tech/documentation/concepts/filtering/)
- Anthropic – “Multi-Agent Tool Use Documentation” (https://docs.anthropic.com/en/docs/build-with-claude/tool-use)
- redis-py – “Python Redis Client Documentation” (https://redis-py.readthedocs.io/en/stable/)