A full written version of the Azure CLI + GitHub Copilot in VS Code session delivered at Global Azure Bootcamp 2026. Covers the .azcli file trick, Copilot Chat for Azure commands, Bicep generation, GitHub Actions workflows, error debugging, and honest limitations — with all demo commands included.
Author: Chandan
Advanced Rust Series Part 4: Lifetime Elision – What the Compiler Infers and When You Must Be Explicit
Most Rust code compiles without a single lifetime annotation. That is not luck – it is lifetime elision, a set of deterministic rules the compiler applies automatically. Understanding those rules tells you exactly when you need to write annotations and why some errors catch you off guard.
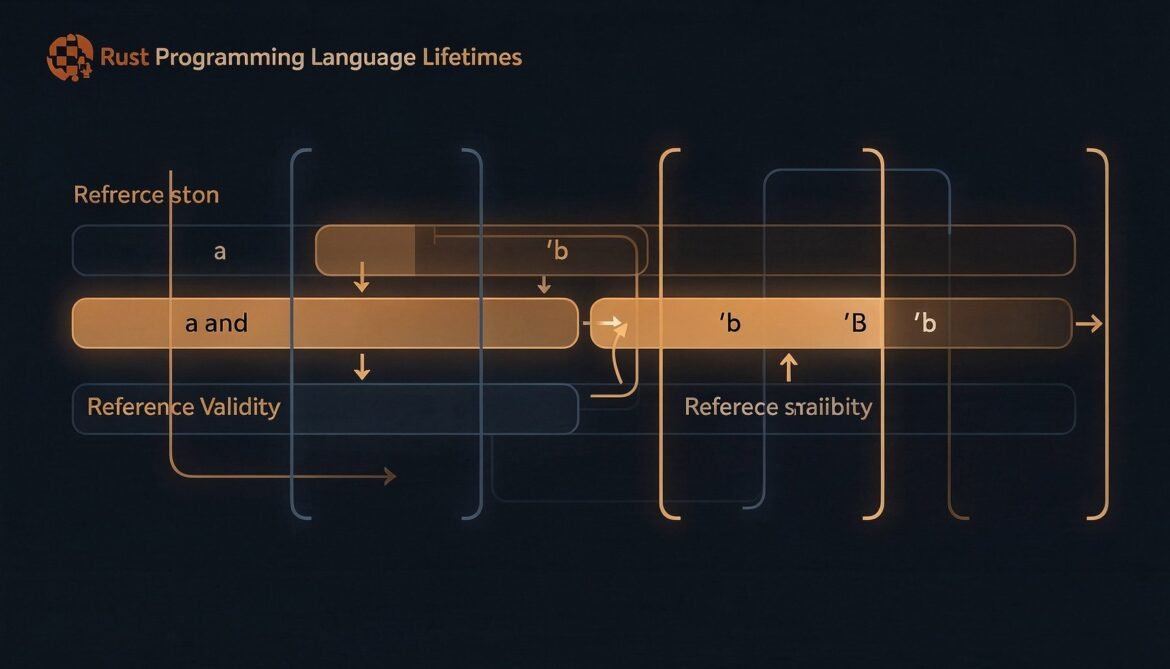
Advanced Rust Series Part 3: Lifetimes Demystified – Why They Exist and How to Read Them
Lifetimes are the part of Rust that scares developers the most. But they are not magic – they are just a way to tell the compiler how long references are valid. Once you understand what the compiler is actually asking, lifetime annotations start to make sense.
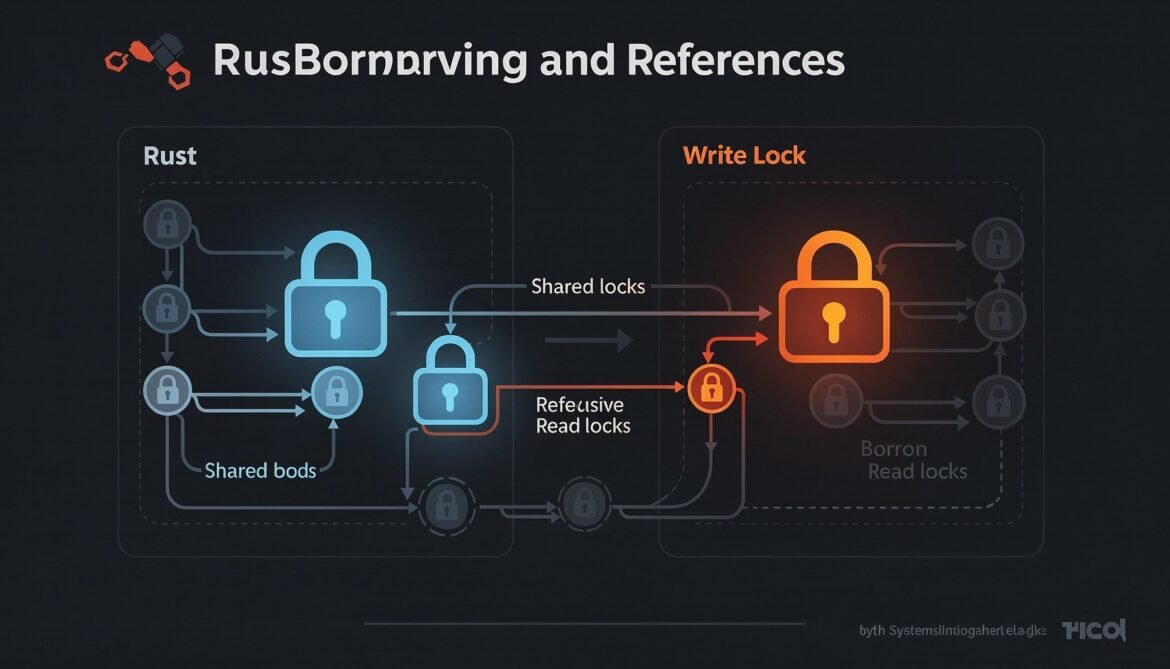
Advanced Rust Series Part 2: Borrowing Rules in Depth – The Borrow Checker Mental Model
The borrow checker is not a random obstacle – it has a clear set of rules and a consistent mental model. Once you internalize how it reasons about your code, you stop fighting it and start working with it. This post breaks down those rules at a level that changes how you write Rust.
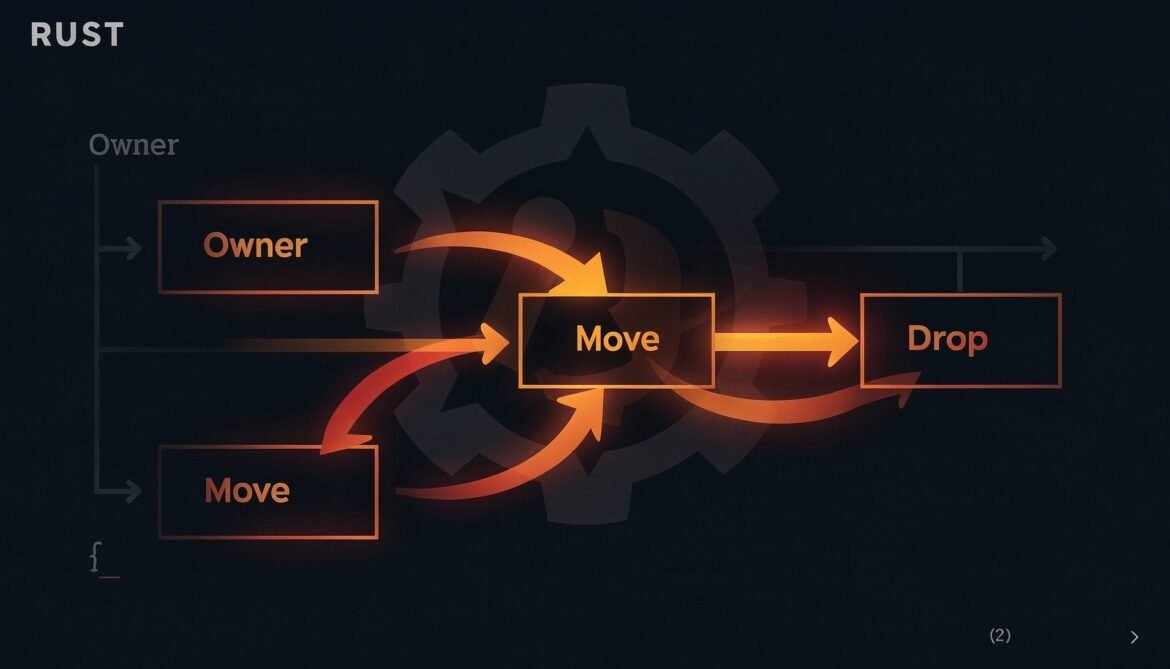
Advanced Rust Series Part 1: The Ownership Model Revisited – Beyond the Basics
Most Rust tutorials cover ownership at the surface level and move on. This post goes deeper – exploring move semantics in real code, the Copy vs Clone distinction that trips up experienced developers, and what ownership actually means for how you design production systems.
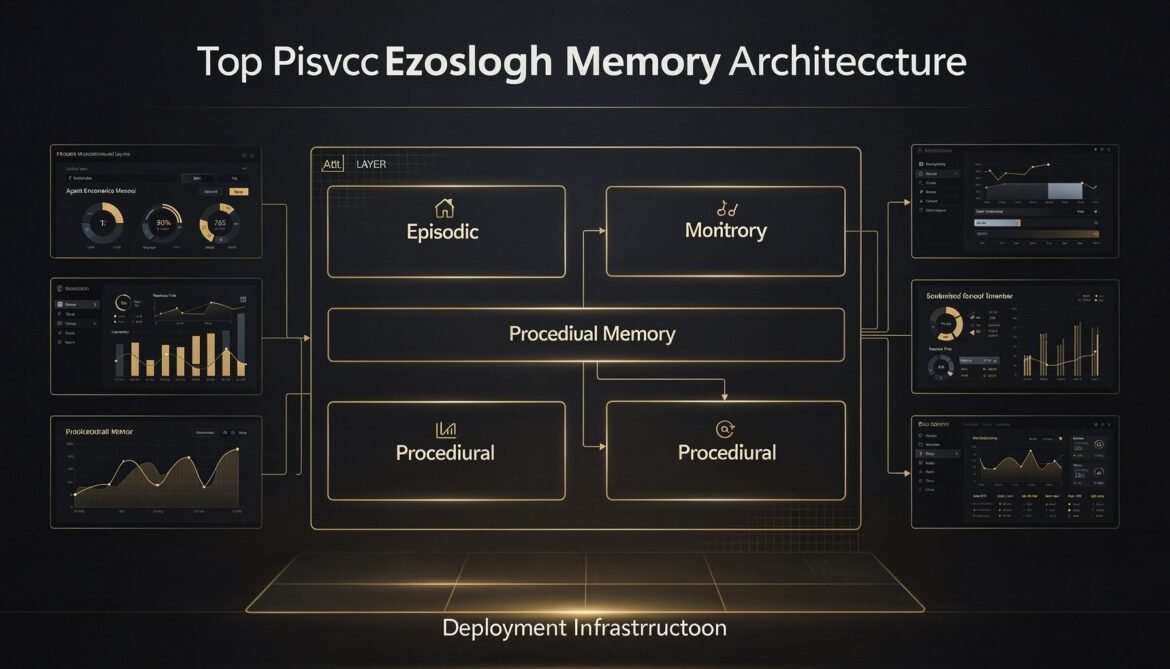
AI Agents with Memory Part 8: Production Memory Architecture – Putting It All Together
Seven parts built the individual layers. This final part assembles them into a complete, deployable production system with a full reference architecture, infrastructure configuration, monitoring setup, cost model, and a decision framework for when to use each memory type.
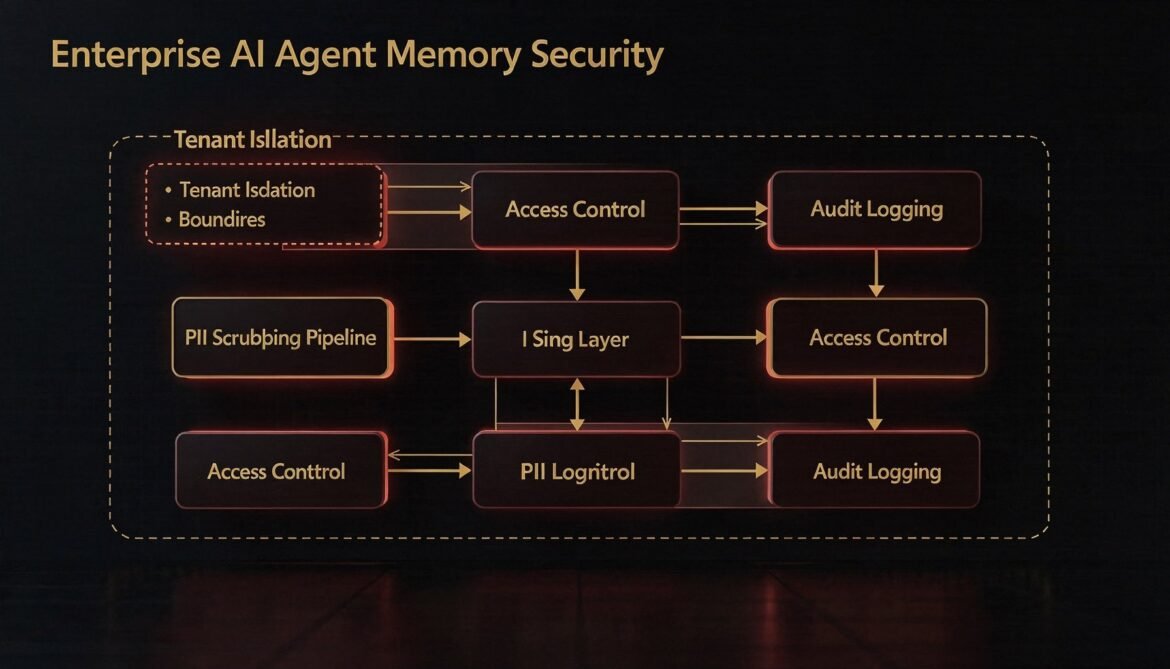
AI Agents with Memory Part 7: Memory Security and Privacy – Tenant Isolation, PII Scrubbing, and Access Control
Agent memory stores are high-value, high-risk assets in enterprise environments. This part builds the security layer: row-level tenant isolation, PII scrubbing before writes, role-based access control for shared scopes, and tamper-evident audit logging in Node.js.
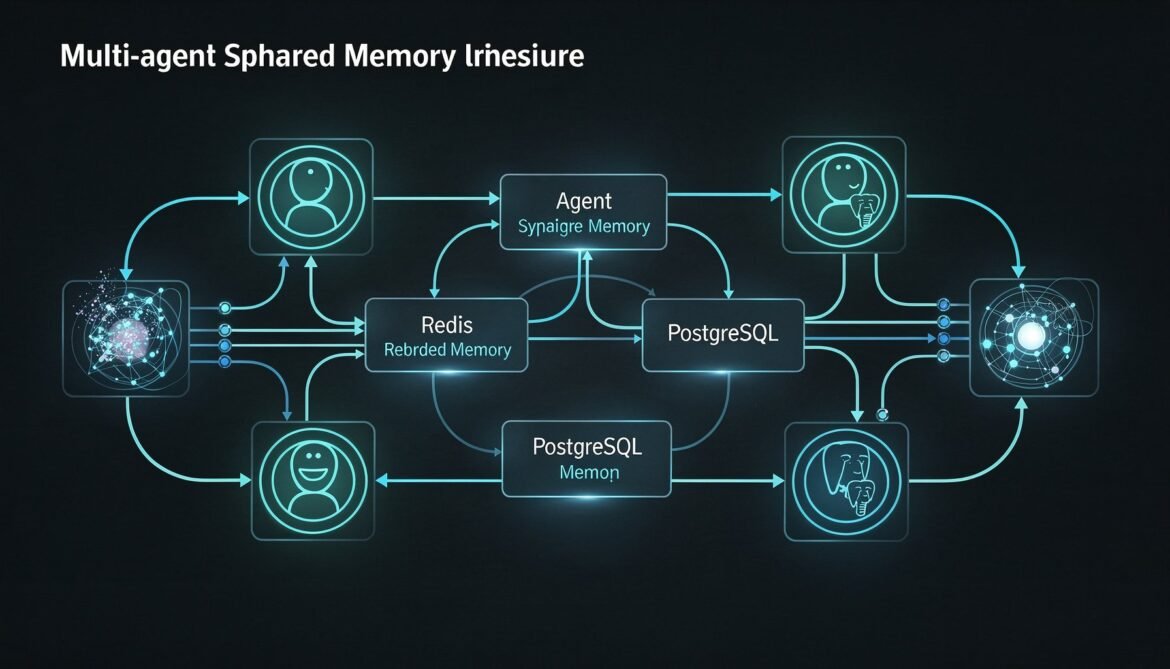
AI Agents with Memory Part 6: Multi-Agent Memory Sharing – Shared Memory Spaces Across Agent Networks with Redis and PostgreSQL
Single-agent memory is only the beginning. Enterprise systems run fleets of specialised agents that need to share knowledge without duplicating work. This part builds a shared memory architecture using Redis for low-latency coordination and PostgreSQL for durable cross-agent event history in Python.
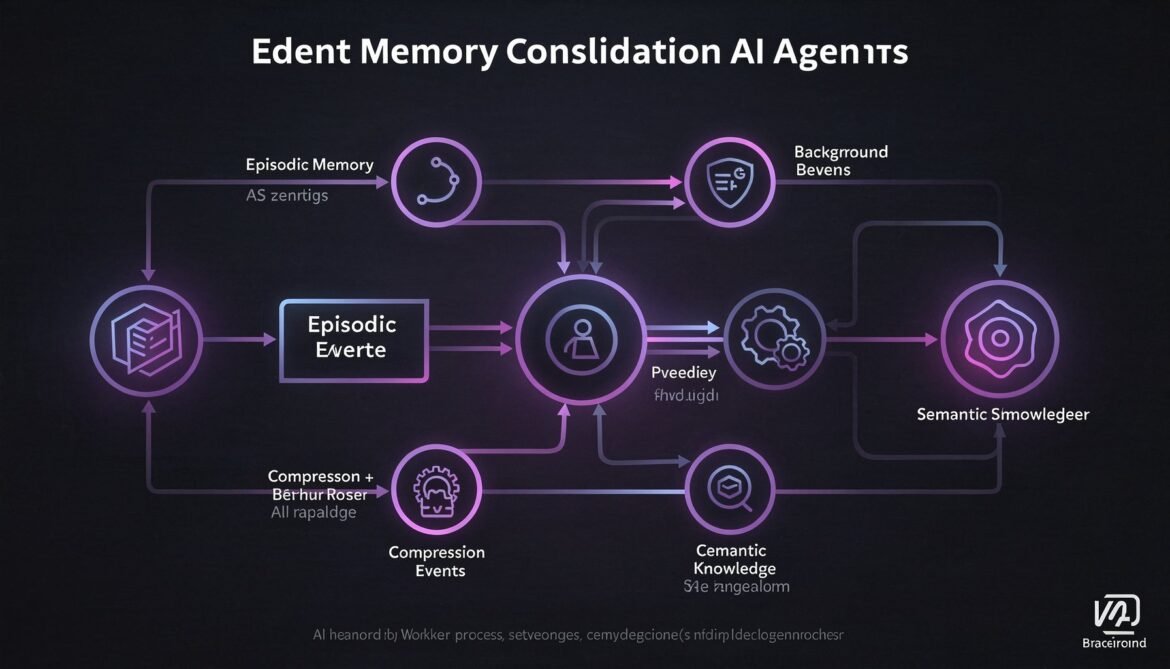
AI Agents with Memory Part 5: Memory Consolidation – Summarising and Compressing Long-Term History with Node.js Background Workers
Episodic memory grows indefinitely. Without consolidation, retrieval degrades and storage costs climb. This part builds a Node.js background worker that compresses episodic memory into semantic knowledge on a rolling schedule, keeping your agent sharp without ballooning your database.

Silicon and Qubits: The April 2026 Tech Turning Point
Meta’s four-chip MTIA silicon roadmap, SpinQ’s $145M quantum computing raise, CavilinQ’s quantum interconnects, and Google’s TurboQuant KV cache breakthrough are all converging in April 2026 to reshape the hardware stack for classical and quantum computing alike.



