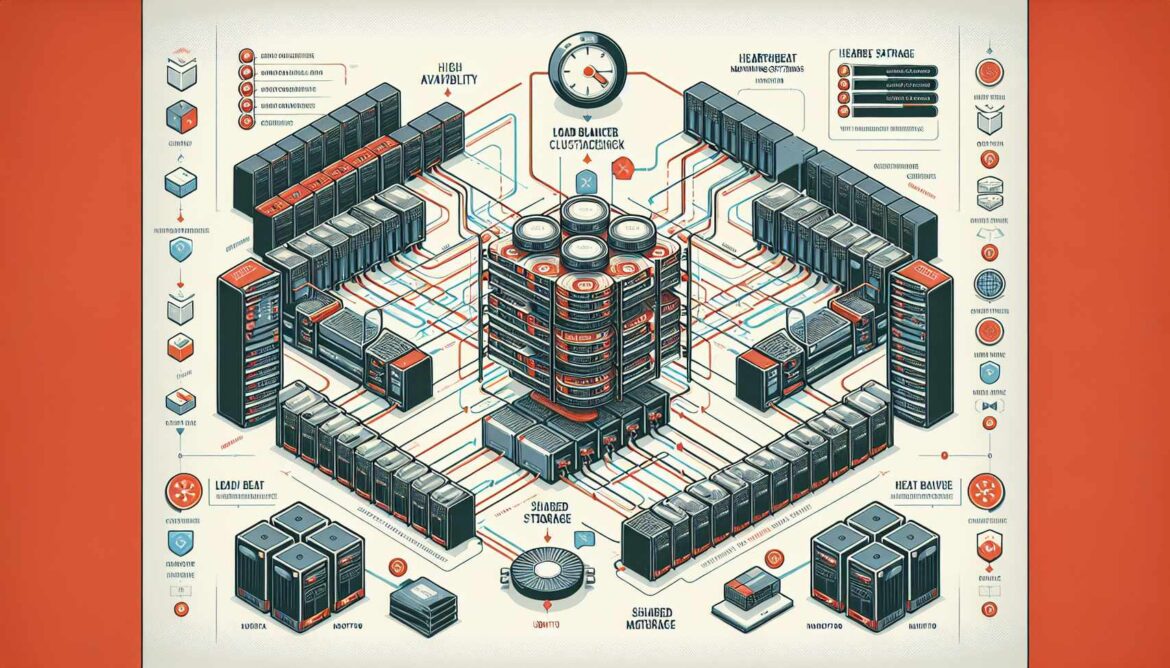
Implement NGINX high availability and clustering on Ubuntu. Learn Keepalived setup, automatic failover, health monitoring, and fault-tolerant infrastructure design.
Tag: clustering
The Complete NGINX on Ubuntu Series: Part 15 – High Availability and Clustering
Implement NGINX high availability and clustering on Ubuntu. Learn Keepalived setup, automatic failover, health monitoring, and zero-downtime operations.

PM2 Clustering and Performance Optimization on Ubuntu
Unlock PM2’s full performance potential with clustering, load balancing, and optimization techniques. Learn to maximize CPU utilization and prevent memory leaks on Ubuntu servers.

Automating Kafka and Redis Startup in WSL: Shell Scripts for Seamless Development
Learn how to create shell scripts that automatically start Kafka (in KRaft mode) and Redis clusters when WSL starts, streamlining your development workflow and eliminating manual setup overhead.

K-Means Clustering: Complete Guide to One of Data Mining’s Most Essential Algorithms
The K-Means clustering algorithm stands as one of the most fundamental and widely-used unsupervised learning algorithms in data mining. Despite its simplicity, K-Means has powered
k-means Clustering
The k-means algorithm, a straightforward and widely used clustering algorithm. Given a set of objects (records), the goal of clustering or segmentation is to divide
The Top 10 Essential Algorithms in Data Mining: A Comprehensive Guide
Data mining has revolutionized how we extract meaningful insights from vast datasets. At the heart of this field lie powerful algorithms that have shaped modern



