Parts 2 through 4 each required provider-specific code: explicit cache_control markers for Claude, automatic prefix detection for GPT-5.4, and named cache objects for Gemini. If your application needs to route between providers, or if you want the flexibility to switch providers without rewriting application logic, you need an abstraction layer that handles all of this transparently.
This part builds a production-ready unified AI gateway in Node.js. The gateway accepts a provider-agnostic request format, translates it into the correct provider-specific structure with proper caching configuration, handles routing based on cost and availability, implements fallback when a provider fails, and tracks cache performance and cost across all providers in a single metrics store.
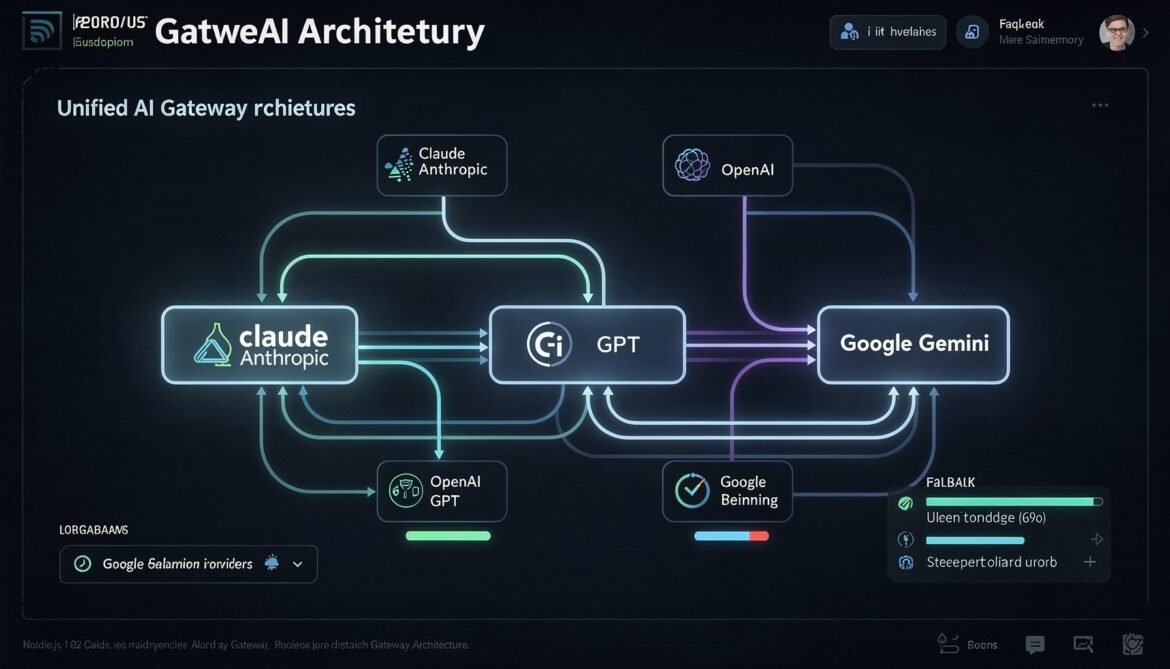
Gateway Architecture Overview
flowchart TD
A[Application Code] --> B[AI Gateway]
B --> C{Routing Strategy}
C -->|Primary| D[Claude Sonnet 4.6\nExplicit cache_control]
C -->|Cost-optimised| E[GPT-5.4\nAutomatic caching]
C -->|Fallback| F[Gemini 3.1 Pro\nImplicit + Explicit cache]
D --> G[Cache Adapter\nClaudeAdapter]
E --> H[Cache Adapter\nOpenAIAdapter]
F --> I[Cache Adapter\nGeminiAdapter]
G & H & I --> J[Response Normaliser]
J --> K[Metrics Collector\nper-provider cache stats]
K --> L[Response to Application]
style B fill:#1e3a5f,color:#fff
style J fill:#166534,color:#fff
style K fill:#713f12,color:#fff
The gateway has four core components. The router decides which provider to use based on your routing strategy. The adapters translate the unified request format into provider-specific API calls with correct caching configuration. The response normaliser converts provider-specific responses into a consistent output format. The metrics collector aggregates cache hit rates, costs, and latency across all providers.
Installation
npm install @anthropic-ai/sdk openai @google/generative-aiProvider Adapters
Each adapter encapsulates the provider-specific caching logic so the rest of the gateway never needs to know which provider it is talking to.
// adapters/claude-adapter.js
import Anthropic from '@anthropic-ai/sdk';
export class ClaudeAdapter {
constructor(apiKey) {
this.client = new Anthropic({ apiKey });
this.name = 'claude';
this.model = 'claude-sonnet-4-6';
}
async complete({ systemPrompt, documents = [], history = [], userMessage, maxTokens = 2048 }) {
const cacheType = 'ephemeral';
// Build system blocks with cache breakpoints
const system = [
{
type: 'text',
text: systemPrompt,
cache_control: { type: cacheType },
},
];
// Add documents as additional system blocks
if (documents.length > 0) {
documents.forEach((doc, i) => {
system.push({
type: 'text',
text: `## ${doc.title}\n\n${doc.content}`,
...(i === documents.length - 1 && { cache_control: { type: cacheType } }),
});
});
}
// Build messages with cache breakpoint on last assistant turn
const messages = history.map((turn, i) => {
const isLastAssistant = turn.role === 'assistant' && i === history.length - 1;
return {
role: turn.role,
content: isLastAssistant
? [{ type: 'text', text: turn.content, cache_control: { type: cacheType } }]
: turn.content,
};
});
messages.push({ role: 'user', content: userMessage });
const response = await this.client.messages.create({
model: this.model,
max_tokens: maxTokens,
system,
messages,
});
return this._normalise(response);
}
_normalise(response) {
const usage = response.usage;
const cachedTokens = usage.cache_read_input_tokens || 0;
const inputTokens = usage.input_tokens;
return {
provider: this.name,
model: this.model,
content: response.content[0].text,
usage: {
inputTokens,
cachedTokens,
outputTokens: usage.output_tokens,
cacheCreationTokens: usage.cache_creation_input_tokens || 0,
cacheHit: cachedTokens > 0,
cacheHitRate: inputTokens > 0 ? cachedTokens / (inputTokens + cachedTokens) : 0,
},
cost: this._calculateCost(usage),
};
}
_calculateCost(usage) {
const rates = { input: 3.0, cacheWrite: 3.75, cacheRead: 0.30, output: 15.0 };
const cached = usage.cache_read_input_tokens || 0;
const created = usage.cache_creation_input_tokens || 0;
const input = usage.input_tokens;
const output = usage.output_tokens;
return {
actualUsd:
(input / 1e6) * rates.input +
(created / 1e6) * rates.cacheWrite +
(cached / 1e6) * rates.cacheRead +
(output / 1e6) * rates.output,
withoutCacheUsd:
((input + cached) / 1e6) * rates.input + (output / 1e6) * rates.output,
};
}
}
// adapters/openai-adapter.js
import OpenAI from 'openai';
export class OpenAIAdapter {
constructor(apiKey) {
this.client = new OpenAI({ apiKey });
this.name = 'openai';
this.model = 'gpt-5.4';
}
async complete({ systemPrompt, documents = [], history = [], userMessage, maxTokens = 2048 }) {
// GPT-5.4: no explicit cache markers needed
// Static content first, dynamic content last is all that matters
let systemContent = systemPrompt;
if (documents.length > 0) {
const docText = documents.map(d => `## ${d.title}\n\n${d.content}`).join('\n\n');
systemContent += `\n\n${docText}`;
}
const messages = [{ role: 'system', content: systemContent }];
// Append history preserving order - never reorder
history.forEach(turn => messages.push({ role: turn.role, content: turn.content }));
messages.push({ role: 'user', content: userMessage });
const response = await this.client.chat.completions.create({
model: this.model,
max_tokens: maxTokens,
messages,
});
return this._normalise(response);
}
_normalise(response) {
const usage = response.usage;
const cachedTokens = usage.prompt_tokens_details?.cached_tokens || 0;
const inputTokens = usage.prompt_tokens;
return {
provider: this.name,
model: this.model,
content: response.choices[0].message.content,
usage: {
inputTokens,
cachedTokens,
outputTokens: usage.completion_tokens,
cacheCreationTokens: 0, // OpenAI does not expose this
cacheHit: cachedTokens > 0,
cacheHitRate: inputTokens > 0 ? cachedTokens / inputTokens : 0,
},
cost: this._calculateCost(usage),
};
}
_calculateCost(usage) {
const rates = { input: 2.50, cacheRead: 0.625, output: 20.0 };
const cached = usage.prompt_tokens_details?.cached_tokens || 0;
const input = usage.prompt_tokens;
const output = usage.completion_tokens;
return {
actualUsd:
((input - cached) / 1e6) * rates.input +
(cached / 1e6) * rates.cacheRead +
(output / 1e6) * rates.output,
withoutCacheUsd:
(input / 1e6) * rates.input + (output / 1e6) * rates.output,
};
}
}
// adapters/gemini-adapter.js
import { GoogleGenerativeAI } from '@google/generative-ai';
export class GeminiAdapter {
constructor(apiKey) {
this.genAI = new GoogleGenerativeAI(apiKey);
this.name = 'gemini';
this.model = 'gemini-3.1-pro';
}
async complete({ systemPrompt, documents = [], history = [], userMessage, maxTokens = 2048 }) {
let systemInstruction = systemPrompt;
if (documents.length > 0) {
const docText = documents.map(d => `## ${d.title}\n\n${d.content}`).join('\n\n');
systemInstruction += `\n\n${docText}`;
}
const model = this.genAI.getGenerativeModel({
model: this.model,
systemInstruction,
generationConfig: { maxOutputTokens: maxTokens },
});
// Build chat history
const geminiHistory = history.map(turn => ({
role: turn.role === 'assistant' ? 'model' : 'user',
parts: [{ text: turn.content }],
}));
const chat = model.startChat({ history: geminiHistory });
const response = await chat.sendMessage(userMessage);
const result = response.response;
return this._normalise(result);
}
_normalise(response) {
const usage = response.usageMetadata;
const cachedTokens = usage?.cachedContentTokenCount || 0;
const inputTokens = usage?.promptTokenCount || 0;
return {
provider: this.name,
model: this.model,
content: response.text(),
usage: {
inputTokens,
cachedTokens,
outputTokens: usage?.candidatesTokenCount || 0,
cacheCreationTokens: 0,
cacheHit: cachedTokens > 0,
cacheHitRate: inputTokens > 0 ? cachedTokens / inputTokens : 0,
},
cost: this._calculateCost(usage),
};
}
_calculateCost(usage) {
const rates = { input: 2.00, cacheRead: 0.50, output: 18.0 };
const cached = usage?.cachedContentTokenCount || 0;
const input = usage?.promptTokenCount || 0;
const output = usage?.candidatesTokenCount || 0;
return {
actualUsd:
((input - cached) / 1e6) * rates.input +
(cached / 1e6) * rates.cacheRead +
(output / 1e6) * rates.output,
withoutCacheUsd:
(input / 1e6) * rates.input + (output / 1e6) * rates.output,
};
}
}
Routing Strategies
flowchart TD
A[Incoming Request] --> B{Routing Strategy}
B -->|primary| C[Always use configured\nprimary provider]
B -->|cost-optimised| D{Estimate token count}
D -->|Large prompt > 10k tokens| E[Use provider with\nbest cache discount\nfor prompt size]
D -->|Small prompt < 10k tokens| F[Use fastest/cheapest\nprovider]
B -->|round-robin| G[Cycle through\navailable providers]
B -->|latency-optimised| H[Use provider with\nlowest recent p95]
C & E & F & G & H --> I{Provider available?}
I -->|Yes| J[Send request]
I -->|No - timeout or error| K[Try next provider\nin fallback chain]
K --> J
// router.js
export class ProviderRouter {
constructor(adapters, strategy = 'primary') {
this.adapters = adapters; // { claude, openai, gemini }
this.strategy = strategy;
this.roundRobinIndex = 0;
this.latencyStats = {
claude: [],
openai: [],
gemini: [],
};
}
select(requestContext = {}) {
switch (this.strategy) {
case 'primary':
return [this.adapters.claude, this.adapters.openai, this.adapters.gemini];
case 'cost-optimised': {
const estimatedTokens = requestContext.estimatedInputTokens || 0;
// For large prompts, Claude's 90% cache read discount beats OpenAI's 75%
// For small prompts, GPT-5.4 has no write premium
const primary = estimatedTokens > 10000 ? 'claude' : 'openai';
const order = [primary, ...Object.keys(this.adapters).filter(k => k !== primary)];
return order.map(k => this.adapters[k]);
}
case 'round-robin': {
const keys = Object.keys(this.adapters);
const key = keys[this.roundRobinIndex % keys.length];
this.roundRobinIndex++;
return [this.adapters[key], ...keys.filter(k => k !== key).map(k => this.adapters[k])];
}
case 'latency-optimised': {
const sorted = Object.entries(this.latencyStats)
.filter(([, times]) => times.length > 0)
.sort(([, a], [, b]) => this._p95(a) - this._p95(b))
.map(([key]) => this.adapters[key]);
return sorted.length ? sorted : Object.values(this.adapters);
}
default:
return Object.values(this.adapters);
}
}
recordLatency(providerName, ms) {
const stats = this.latencyStats[providerName];
stats.push(ms);
// Keep last 100 measurements
if (stats.length > 100) stats.shift();
}
_p95(times) {
const sorted = [...times].sort((a, b) => a - b);
return sorted[Math.floor(sorted.length * 0.95)] || 0;
}
}
Gateway Metrics Collector
// gateway-metrics.js
export class GatewayMetrics {
constructor() {
this.providers = {
claude: this._emptyStats(),
openai: this._emptyStats(),
gemini: this._emptyStats(),
};
this.errors = [];
}
_emptyStats() {
return {
requests: 0,
cacheHits: 0,
totalInputTokens: 0,
totalCachedTokens: 0,
totalOutputTokens: 0,
totalActualCostUsd: 0,
totalWithoutCacheCostUsd: 0,
latenciesMs: [],
failures: 0,
};
}
record(providerName, result, latencyMs) {
const s = this.providers[providerName];
if (!s) return;
s.requests++;
s.totalInputTokens += result.usage.inputTokens;
s.totalCachedTokens += result.usage.cachedTokens;
s.totalOutputTokens += result.usage.outputTokens;
s.totalActualCostUsd += result.cost.actualUsd;
s.totalWithoutCacheCostUsd += result.cost.withoutCacheUsd;
s.latenciesMs.push(latencyMs);
if (s.latenciesMs.length > 500) s.latenciesMs.shift();
if (result.usage.cacheHit) s.cacheHits++;
}
recordError(providerName, error) {
if (this.providers[providerName]) {
this.providers[providerName].failures++;
}
this.errors.push({ provider: providerName, message: error.message, timestamp: Date.now() });
if (this.errors.length > 100) this.errors.shift();
}
getSummary() {
const summary = {};
for (const [name, s] of Object.entries(this.providers)) {
if (s.requests === 0) continue;
const sortedLatencies = [...s.latenciesMs].sort((a, b) => a - b);
const p50 = sortedLatencies[Math.floor(sortedLatencies.length * 0.50)] || 0;
const p95 = sortedLatencies[Math.floor(sortedLatencies.length * 0.95)] || 0;
summary[name] = {
requests: s.requests,
failures: s.failures,
errorRate: s.requests > 0 ? ((s.failures / s.requests) * 100).toFixed(1) + '%' : '0%',
cacheHitRate: s.requests > 0 ? ((s.cacheHits / s.requests) * 100).toFixed(1) + '%' : '0%',
tokenCacheEfficiency: s.totalInputTokens > 0
? ((s.totalCachedTokens / s.totalInputTokens) * 100).toFixed(1) + '%'
: '0%',
totalActualCostUsd: s.totalActualCostUsd.toFixed(4),
totalSavingsUsd: (s.totalWithoutCacheCostUsd - s.totalActualCostUsd).toFixed(4),
savingsPercent: s.totalWithoutCacheCostUsd > 0
? (((s.totalWithoutCacheCostUsd - s.totalActualCostUsd) / s.totalWithoutCacheCostUsd) * 100).toFixed(1) + '%'
: '0%',
latency: { p50Ms: p50, p95Ms: p95 },
};
}
return summary;
}
}
The Gateway Core
// ai-gateway.js
import { ClaudeAdapter } from './adapters/claude-adapter.js';
import { OpenAIAdapter } from './adapters/openai-adapter.js';
import { GeminiAdapter } from './adapters/gemini-adapter.js';
import { ProviderRouter } from './router.js';
import { GatewayMetrics } from './gateway-metrics.js';
export class AIGateway {
constructor({
anthropicApiKey,
openaiApiKey,
geminiApiKey,
strategy = 'primary',
maxRetries = 2,
timeoutMs = 30000,
}) {
const adapters = {
claude: new ClaudeAdapter(anthropicApiKey),
openai: new OpenAIAdapter(openaiApiKey),
gemini: new GeminiAdapter(geminiApiKey),
};
this.router = new ProviderRouter(adapters, strategy);
this.metrics = new GatewayMetrics();
this.maxRetries = maxRetries;
this.timeoutMs = timeoutMs;
}
async complete(request) {
const providerChain = this.router.select({
estimatedInputTokens: this._estimateTokens(request),
});
let lastError = null;
for (const adapter of providerChain) {
const start = Date.now();
try {
const result = await this._withTimeout(
adapter.complete(request),
this.timeoutMs
);
const latencyMs = Date.now() - start;
this.metrics.record(adapter.name, result, latencyMs);
this.router.recordLatency(adapter.name, latencyMs);
return { ...result, latencyMs, fallbackUsed: adapter !== providerChain[0] };
} catch (err) {
lastError = err;
this.metrics.recordError(adapter.name, err);
console.warn(`[AIGateway] ${adapter.name} failed: ${err.message}. Trying next provider.`);
}
}
throw new Error(
`All providers failed. Last error: ${lastError?.message}`
);
}
_withTimeout(promise, ms) {
return Promise.race([
promise,
new Promise((_, reject) =>
setTimeout(() => reject(new Error(`Request timed out after ${ms}ms`)), ms)
),
]);
}
_estimateTokens(request) {
const systemText = request.systemPrompt || '';
const docText = (request.documents || []).map(d => d.content).join(' ');
const historyText = (request.history || []).map(t => t.content).join(' ');
const query = request.userMessage || '';
return Math.ceil((systemText + docText + historyText + query).length / 4);
}
getMetrics() {
return this.metrics.getSummary();
}
setStrategy(strategy) {
this.router.strategy = strategy;
}
}
Conversation Session Manager
The session manager wraps the gateway to maintain conversation state and route consistently across turns. Consistency matters because switching providers mid-conversation loses cached context and forces a full reprocess on the new provider.
// gateway-session.js
export class GatewaySession {
constructor(gateway, { systemPrompt, documents = [], stickyProvider = true }) {
this.gateway = gateway;
this.systemPrompt = systemPrompt;
this.documents = documents;
this.stickyProvider = stickyProvider;
this.history = [];
this.preferredProvider = null;
this.totalSavingsUsd = 0;
this.turnCount = 0;
}
async send(userMessage) {
// Once a provider is chosen for this session, stick with it
// to preserve cached context and maximise hit rates
const request = {
systemPrompt: this.systemPrompt,
documents: this.documents,
history: this.history,
userMessage,
};
// If stickyProvider mode and we have a preferred provider,
// temporarily override strategy to use it
if (this.stickyProvider && this.preferredProvider) {
this.gateway.setStrategy('primary');
// Note: In a full implementation you would pin to the specific adapter
}
const result = await this.gateway.complete(request);
// Record which provider was used on first turn
if (!this.preferredProvider) {
this.preferredProvider = result.provider;
}
// Update history for next turn
this.history.push({ role: 'user', content: userMessage });
this.history.push({ role: 'assistant', content: result.content });
this.totalSavingsUsd += result.cost.withoutCacheUsd - result.cost.actualUsd;
this.turnCount++;
return {
reply: result.content,
provider: result.provider,
model: result.model,
cacheHit: result.usage.cacheHit,
cachedTokens: result.usage.cachedTokens,
turnNumber: this.turnCount,
latencyMs: result.latencyMs,
fallbackUsed: result.fallbackUsed,
turnSavingsUsd: result.cost.withoutCacheUsd - result.cost.actualUsd,
cumulativeSavingsUsd: this.totalSavingsUsd,
};
}
reset() {
this.history = [];
this.preferredProvider = null;
this.totalSavingsUsd = 0;
this.turnCount = 0;
}
}
Complete Usage Example
// example.js
import { AIGateway } from './ai-gateway.js';
import { GatewaySession } from './gateway-session.js';
const gateway = new AIGateway({
anthropicApiKey: process.env.ANTHROPIC_API_KEY,
openaiApiKey: process.env.OPENAI_API_KEY,
geminiApiKey: process.env.GEMINI_API_KEY,
strategy: 'cost-optimised',
maxRetries: 2,
timeoutMs: 30000,
});
const SYSTEM_PROMPT = `You are a senior enterprise cloud architect.
Provide precise, production-focused guidance with working code examples.
Consider cost, security, and operational complexity in every recommendation.`;
const SHARED_DOCS = [
{
title: 'Infrastructure Standards v3.1',
content: `All production services must run on Kubernetes 1.31+.
Minimum replicas: 3 for production, 2 for staging.
Health checks required: /health (liveness), /ready (readiness).
All secrets via Azure Key Vault or AWS Secrets Manager only.
Observability stack: OpenTelemetry + Grafana + Loki mandatory.`,
},
];
const session = new GatewaySession(gateway, {
systemPrompt: SYSTEM_PROMPT,
documents: SHARED_DOCS,
stickyProvider: true,
});
const questions = [
'What is the right approach for blue-green deployments on our Kubernetes setup?',
'How should we handle database migrations in that deployment model?',
'What monitoring should we configure for the deployment pipeline?',
];
console.log('Starting multi-turn session with gateway...\n');
for (const question of questions) {
const result = await session.send(question);
console.log(`[Turn ${result.turnNumber}] Provider: ${result.provider} | Cache hit: ${result.cacheHit} | Cached tokens: ${result.cachedTokens}`);
console.log(`Latency: ${result.latencyMs}ms | Fallback used: ${result.fallbackUsed}`);
console.log(`Savings this turn: $${result.turnSavingsUsd.toFixed(6)}`);
console.log(`Q: ${question}`);
console.log(`A: ${result.reply.substring(0, 150)}...\n`);
}
console.log('\n--- Gateway Metrics Summary ---');
console.log(JSON.stringify(gateway.getMetrics(), null, 2));
console.log(`\nTotal session savings: $${session.cumulativeSavingsUsd.toFixed(4)}`);
Health Check and Admin Endpoint
For production deployments, expose a health and metrics endpoint so your platform team can monitor gateway status and cache efficiency without digging through logs.
// gateway-server.js - minimal Express wrapper
import express from 'express';
import { AIGateway } from './ai-gateway.js';
const app = express();
app.use(express.json());
const gateway = new AIGateway({
anthropicApiKey: process.env.ANTHROPIC_API_KEY,
openaiApiKey: process.env.OPENAI_API_KEY,
geminiApiKey: process.env.GEMINI_API_KEY,
strategy: process.env.ROUTING_STRATEGY || 'cost-optimised',
});
// Main completion endpoint
app.post('/v1/complete', async (req, res) => {
try {
const { systemPrompt, documents, history, userMessage, maxTokens } = req.body;
const result = await gateway.complete({ systemPrompt, documents, history, userMessage, maxTokens });
res.json(result);
} catch (err) {
res.status(500).json({ error: err.message });
}
});
// Metrics endpoint for observability dashboards
app.get('/metrics', (req, res) => {
res.json({
timestamp: new Date().toISOString(),
providers: gateway.getMetrics(),
});
});
// Routing strategy override (for gradual provider migration)
app.put('/config/strategy', (req, res) => {
const { strategy } = req.body;
const valid = ['primary', 'cost-optimised', 'round-robin', 'latency-optimised'];
if (!valid.includes(strategy)) {
return res.status(400).json({ error: `Invalid strategy. Must be one of: ${valid.join(', ')}` });
}
gateway.setStrategy(strategy);
res.json({ strategy, updated: true });
});
// Liveness probe
app.get('/health', (req, res) => res.json({ status: 'ok' }));
app.listen(3000, () => console.log('[AIGateway] Listening on port 3000'));
When to Use a Gateway vs Direct Provider SDKs
A gateway adds a layer of abstraction that has real benefits but also real costs. Here is when it is the right choice and when it is not.
| Scenario | Gateway | Direct SDK |
|---|---|---|
| Single provider, simple app | Overkill | Better choice |
| Multi-provider routing needed | Right choice | Significant duplication |
| Provider failover required | Right choice | Complex to implement manually |
| Unified cost tracking across providers | Right choice | Requires separate aggregation |
| Gradual provider migration | Right choice | Requires code changes |
| Latency-critical single-provider path | Adds overhead | Better choice |
What Is Next
Part 8 is the final part of this series. It covers production monitoring and ROI: how to build cache hit rate dashboards, measure time-to-first-token improvements, calculate real-world cost savings, and make the business case for caching investment using data from your own system. It also covers how to detect and alert on cache regression, which happens silently whenever a prompt change or traffic pattern shift causes hit rates to drop.
References
- OpenAI – “Introducing GPT-5.4” (https://openai.com/index/introducing-gpt-5-4/)
- Anthropic – “Prompt Caching Documentation” (https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching)
- Google DeepMind – “Gemini 3.1 Pro” (https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/)
- OpenRouter – “Prompt Caching Best Practices” (https://openrouter.ai/docs/guides/best-practices/prompt-caching)
- DigitalOcean – “Prompt Caching Explained: OpenAI, Claude, and Gemini” (https://www.digitalocean.com/community/tutorials/prompt-caching-explained)