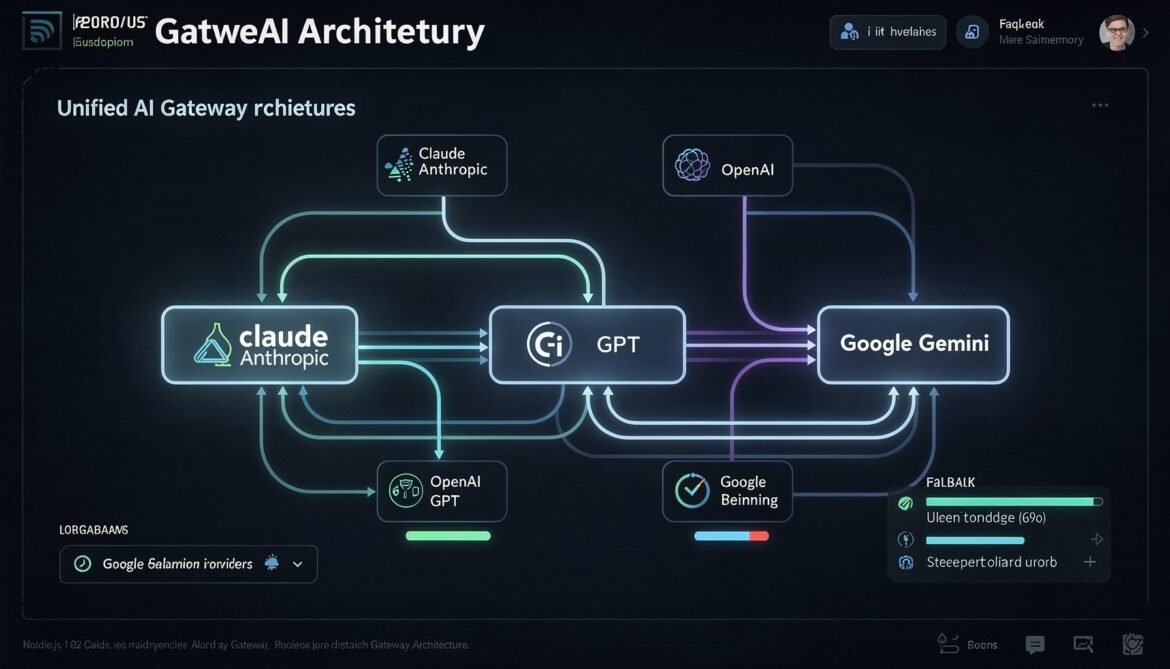
A unified AI gateway abstracts over provider-specific caching implementations, routing logic, and fallback handling. This part builds a production-ready Node.js gateway that handles Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro transparently, with cross-provider cost tracking and cache hit monitoring.
Tag: Gemini 3.1 Pro

Context Caching with Gemini 3.1 Pro and Flash-Lite: Implicit vs Explicit Caching, Storage Costs, and Python Production Implementation
Google Gemini 3.1 Pro and Flash-Lite offer both implicit and explicit context caching, with the most generous default TTL of any major provider at one hour. This part covers how both modes work, how to account for storage costs, and a complete Python production implementation for Vertex AI and the Gemini API.
Prompt Caching and Context Engineering in Production: What It Is and Why It Matters in 2026
Prompt caching is one of the most impactful yet underused techniques in enterprise AI today. This first part of the series explains what it is, how it works under the hood, and why it should be a default part of your production AI architecture in 2026.



