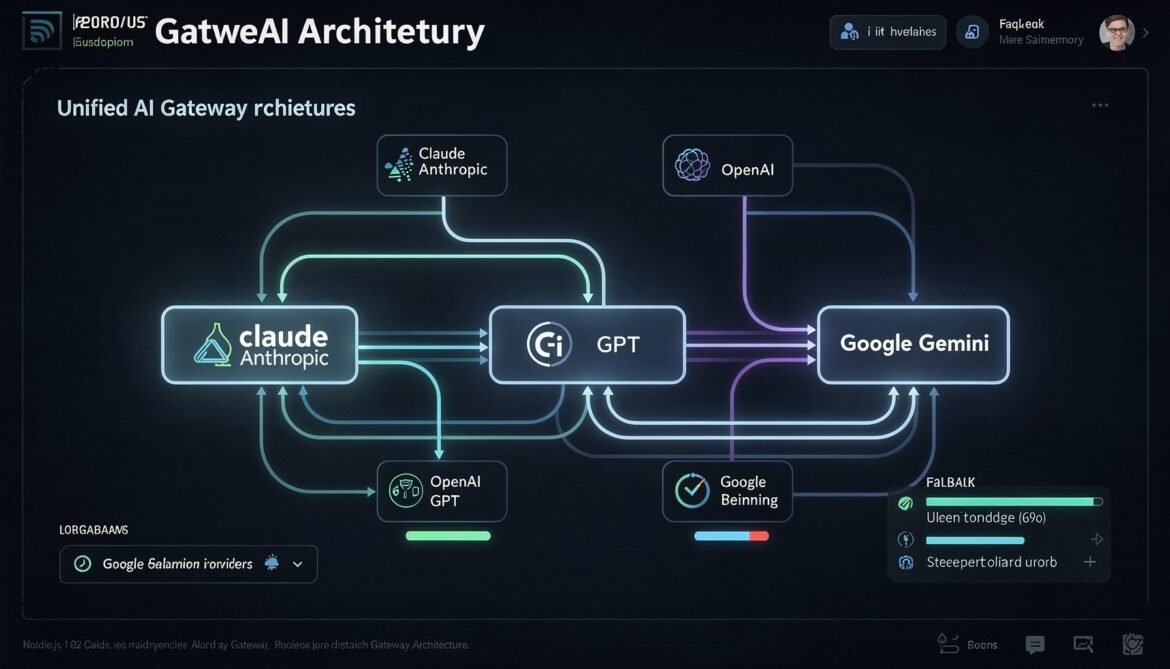
A unified AI gateway abstracts over provider-specific caching implementations, routing logic, and fallback handling. This part builds a production-ready Node.js gateway that handles Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro transparently, with cross-provider cost tracking and cache hit monitoring.
Tag: GPT-5.4
Context Engineering Strategies: Designing Prompts for Cache Efficiency, RAG Pipelines, and Production Scale
Context engineering is the discipline of designing what goes into your LLM context window, in what order, and how to structure it for maximum cache efficiency, retrieval quality, and cost control. This part covers static-first architecture, cache-aware RAG design, prompt versioning, and token budget management.

Prompt Caching with GPT-5.4: Automatic Caching, Tool Search, and C# Production Implementation
GPT-5.4 makes prompt caching automatic with no configuration required. This part covers how OpenAI’s caching works under the hood, how to structure prompts for maximum hit rates, how the new Tool Search feature reduces agent token costs, and a full production C# implementation with cost tracking.
Prompt Caching and Context Engineering in Production: What It Is and Why It Matters in 2026
Prompt caching is one of the most impactful yet underused techniques in enterprise AI today. This first part of the series explains what it is, how it works under the hood, and why it should be a default part of your production AI architecture in 2026.

The LLM Landscape in March 2026: Open Source Catches Up, Local AI Goes Mainstream
In the span of a single week in early March 2026, more than twelve major AI models shipped across language, video, and spatial reasoning domains.



