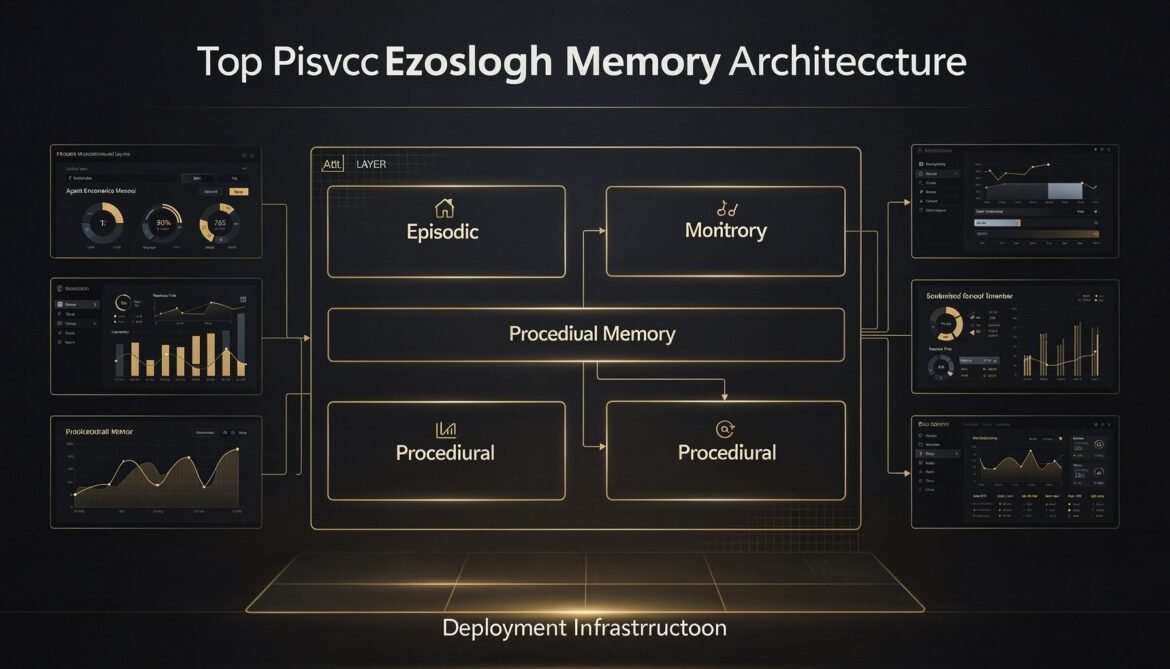
Seven parts built the individual layers. This final part assembles them into a complete, deployable production system with a full reference architecture, infrastructure configuration, monitoring setup, cost model, and a decision framework for when to use each memory type.
Category: AI
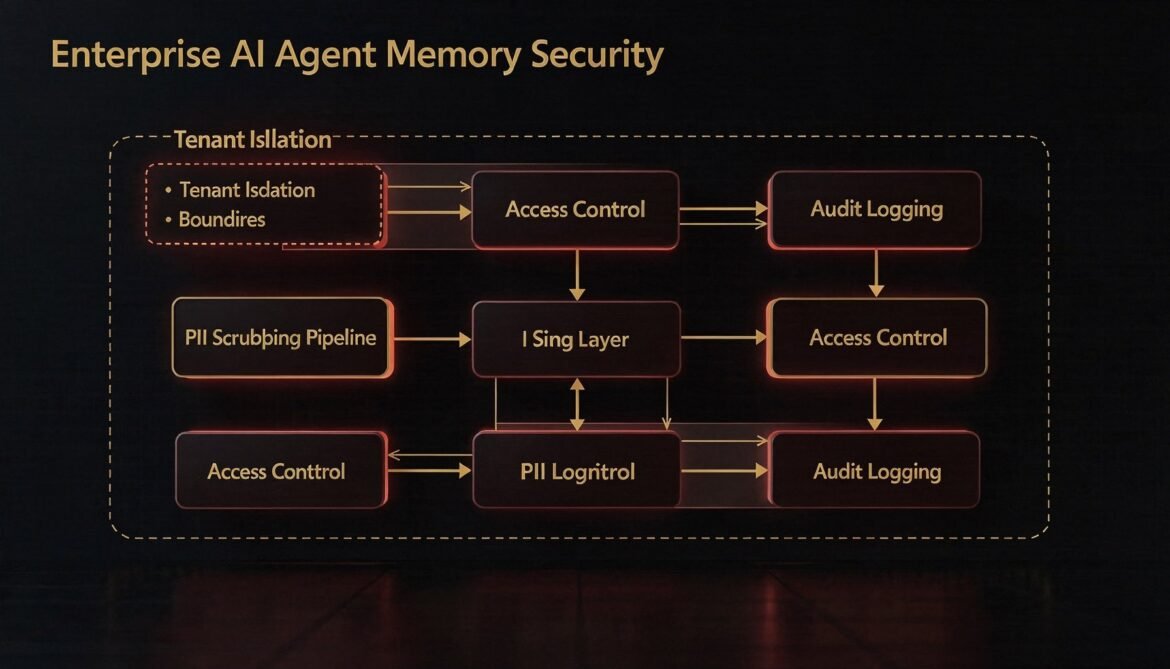
AI Agents with Memory Part 7: Memory Security and Privacy – Tenant Isolation, PII Scrubbing, and Access Control
Agent memory stores are high-value, high-risk assets in enterprise environments. This part builds the security layer: row-level tenant isolation, PII scrubbing before writes, role-based access control for shared scopes, and tamper-evident audit logging in Node.js.
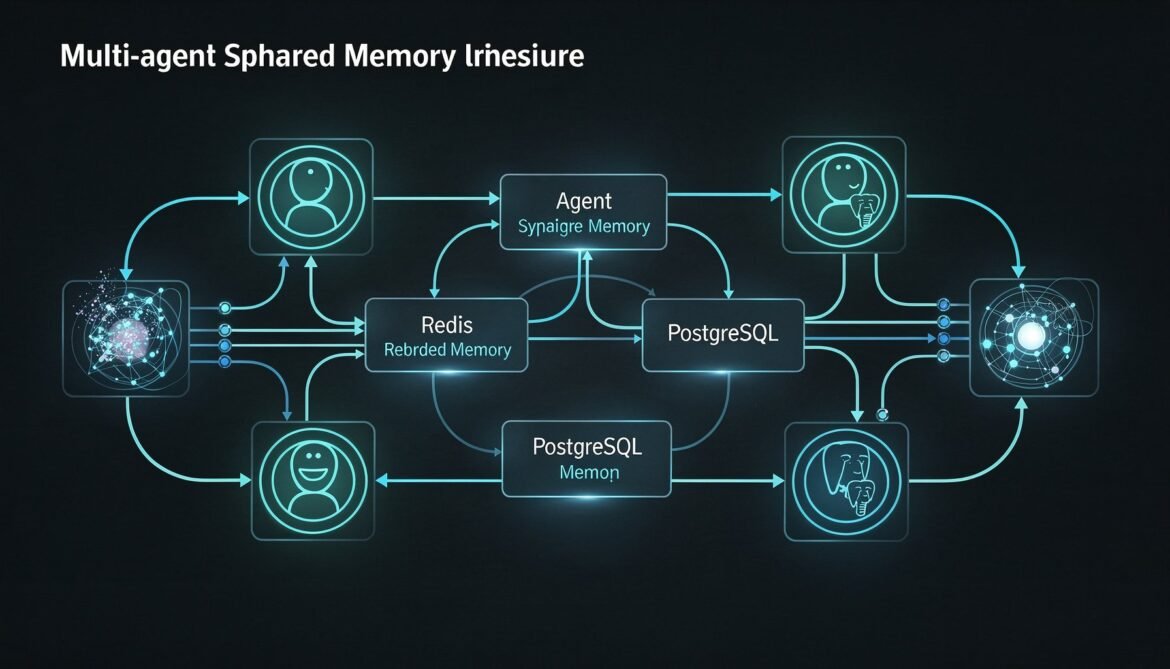
AI Agents with Memory Part 6: Multi-Agent Memory Sharing – Shared Memory Spaces Across Agent Networks with Redis and PostgreSQL
Single-agent memory is only the beginning. Enterprise systems run fleets of specialised agents that need to share knowledge without duplicating work. This part builds a shared memory architecture using Redis for low-latency coordination and PostgreSQL for durable cross-agent event history in Python.
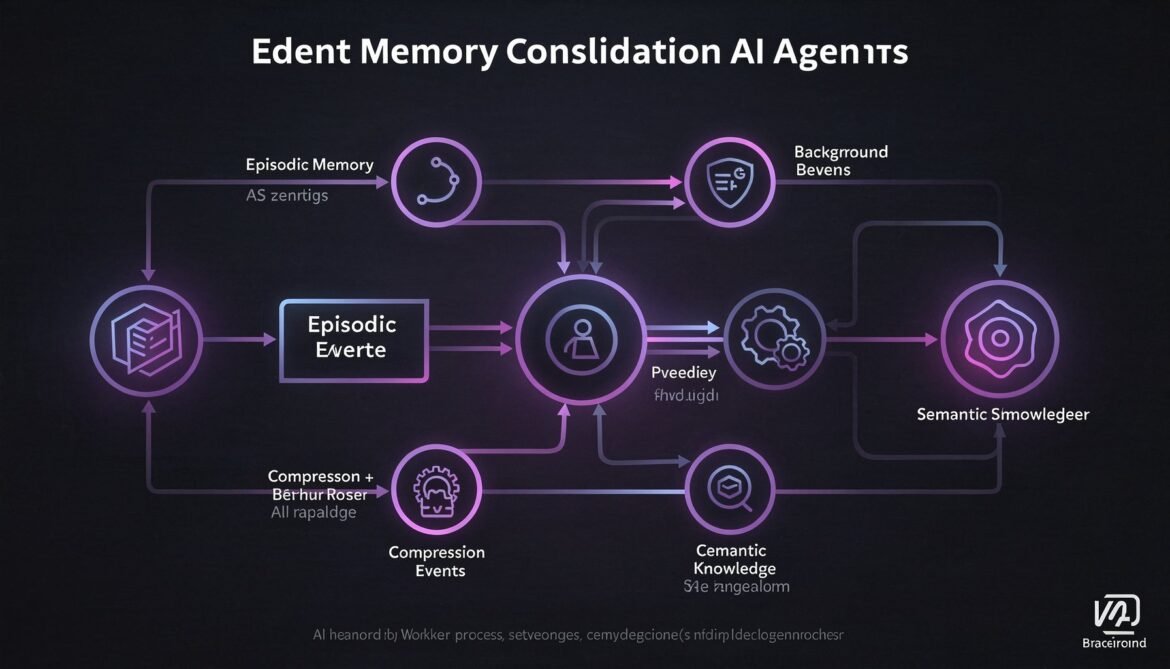
AI Agents with Memory Part 5: Memory Consolidation – Summarising and Compressing Long-Term History with Node.js Background Workers
Episodic memory grows indefinitely. Without consolidation, retrieval degrades and storage costs climb. This part builds a Node.js background worker that compresses episodic memory into semantic knowledge on a rolling schedule, keeping your agent sharp without ballooning your database.
AI Agents with Memory Part 4: Procedural Memory – Agents That Learn From Past Actions Using C#
Episodic memory records what happened. Semantic memory stores what is known. Procedural memory stores how things are done. This part builds a production procedural memory system in C# that records successful tool sequences and problem-solving patterns so agents get measurably better with every session.

The April 2026 AI Report: Model Wars, a 100x Energy Breakthrough, and the EU AI Act Countdown
A comprehensive look at the biggest AI stories of April 2026: the model leaderboard reshuffle driven by Claude Opus 4.6 and Gemini 3.1 Ultra, a 100x energy efficiency breakthrough from Tufts University using neuro-symbolic AI, the August 2026 EU AI Act compliance deadline bearing down on enterprises, and major infrastructure bets from Anthropic, Snowflake, and Microsoft.
AI Agents with Memory Part 3: Semantic Memory – Building a Long-Term Knowledge Layer with Qdrant and Python
Episodic memory records what happened. Semantic memory stores what the agent has learned. This part builds a production semantic memory layer using Qdrant and Python, with fact extraction, importance-weighted upserts, and similarity retrieval that lets agents build genuine knowledge about users and domains over time.
AI Agents with Memory Part 2: Episodic Memory – Storing and Retrieving Conversation History at Scale with PostgreSQL, pgvector, and Node.js
Episodic memory is what lets an agent remember what happened in past sessions. This part builds a complete production episodic memory system using PostgreSQL with pgvector, implementing hybrid time-based and semantic retrieval in Node.js so your agent never starts from zero again.
AI Agents with Memory: Why Single-Session Agents Fail in Enterprise and the Three Memory Types That Fix It
Most agent guides cover single-session work. Enterprise agents need persistent memory across sessions. This first part explains why stateless agents break down at enterprise scale, introduces the three memory types that solve it, and maps out the architecture this series will build.
Production Monitoring for LLM Caching: Cache Hit Rate Dashboards, TTFT Measurement, and ROI Calculation
Shipping caching without monitoring is flying blind. This final part covers how to build cache hit rate dashboards, measure time-to-first-token improvements, calculate real cost savings with accuracy, detect cache regression before users notice, and build the business case for continued caching investment.



