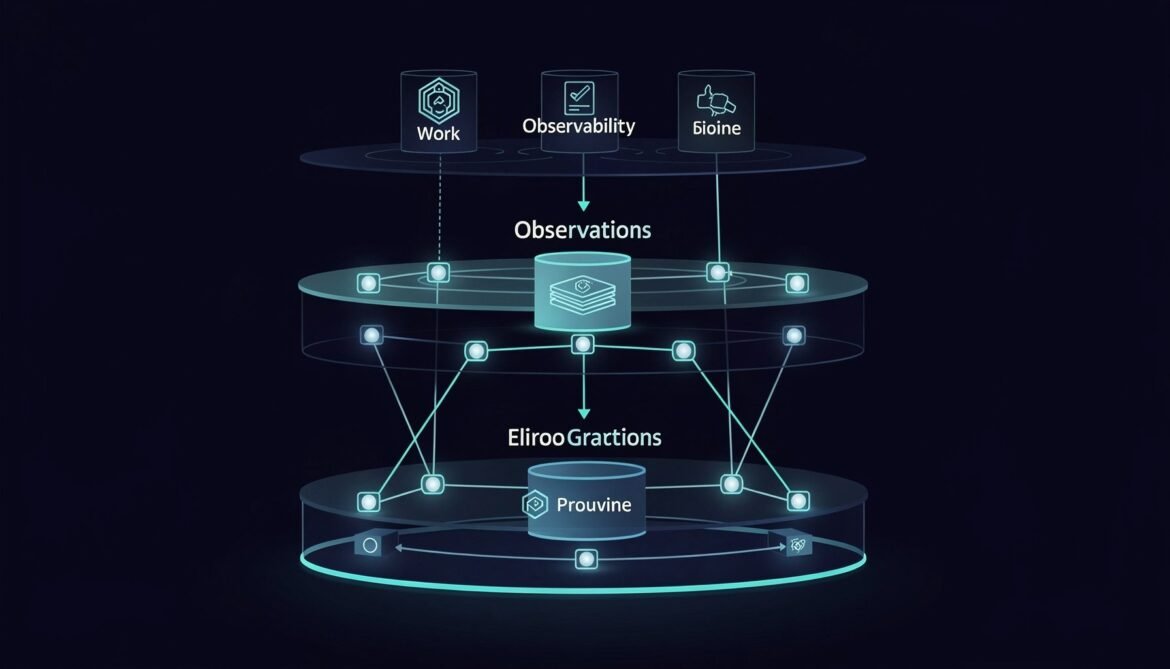
Seven posts, seven production systems. This final installment assembles every piece — distributed tracing, metrics, evaluation, prompt versioning, RAG observability, and cost governance — into one reference architecture with a phased implementation checklist you can start using this week.
Tag: AI Observability
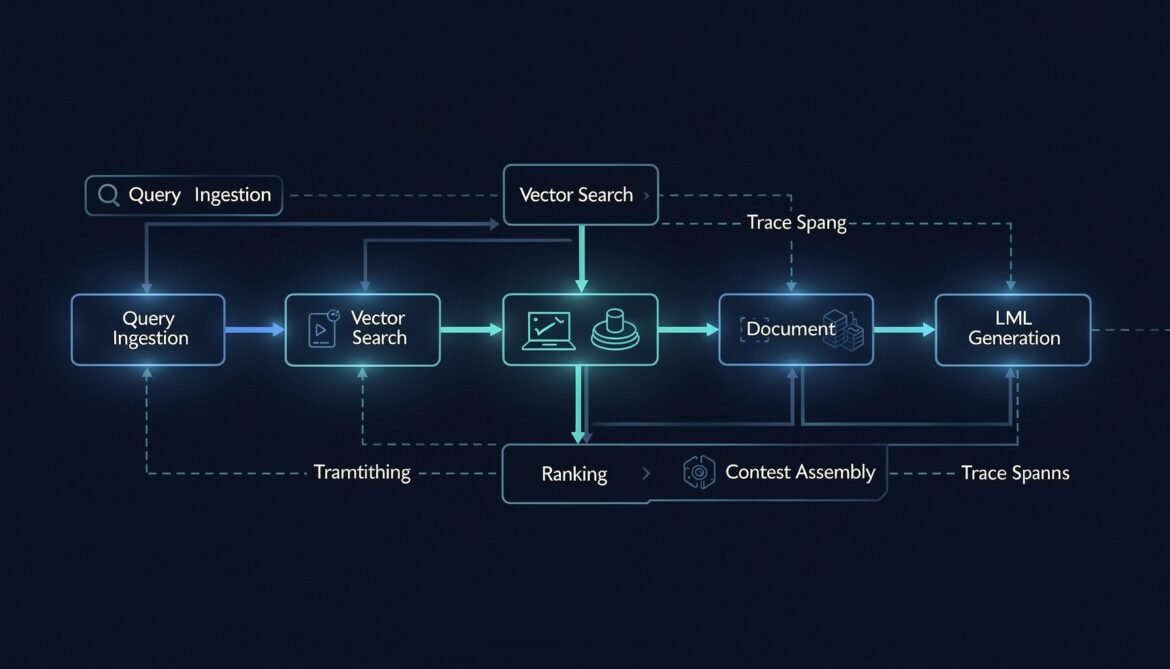
RAG Pipeline Observability: Tracing Retrieval, Chunking, and Embedding Quality
A RAG pipeline has five distinct places it can fail before the LLM ever sees your context. This post instruments every stage — query embedding, vector search, document ranking, context assembly, and generation — with OpenTelemetry spans and quality metrics, in Node.js, Python, and C#.
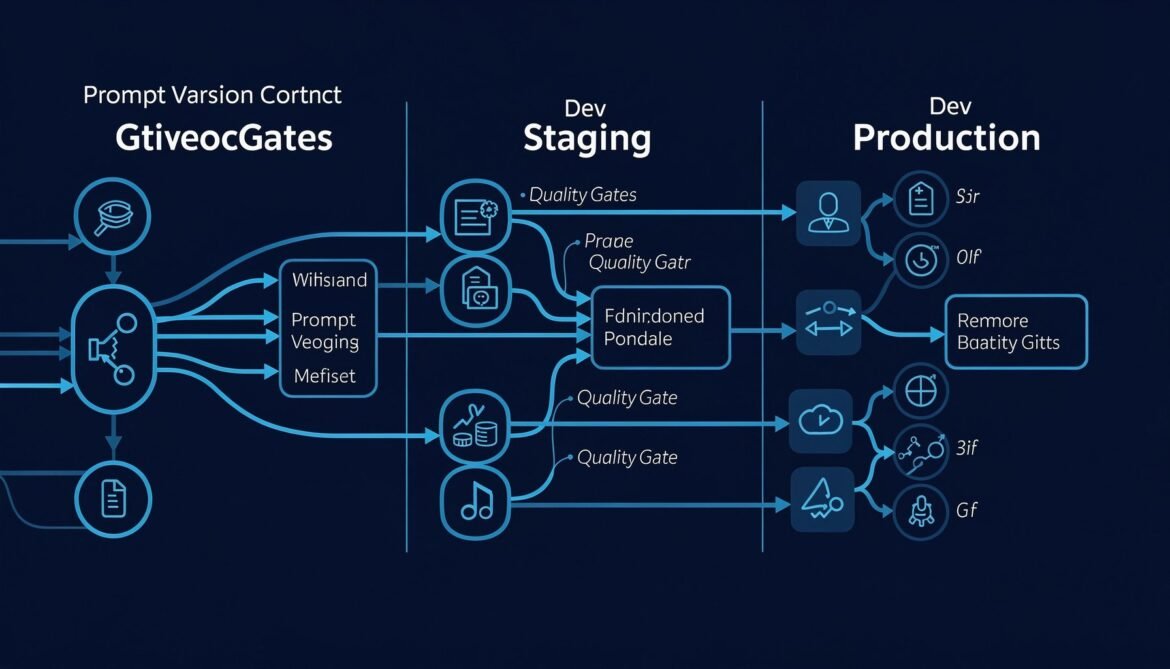
Prompt Management and Versioning: Treating Prompts as Production Code
Prompt changes are production changes. A wording edit at 3pm on a Friday can silently degrade thousands of responses with no error signal. This post builds a production-grade prompt management system with versioning, A/B testing, quality gates, and rollback in Node.js, Python, and C#.
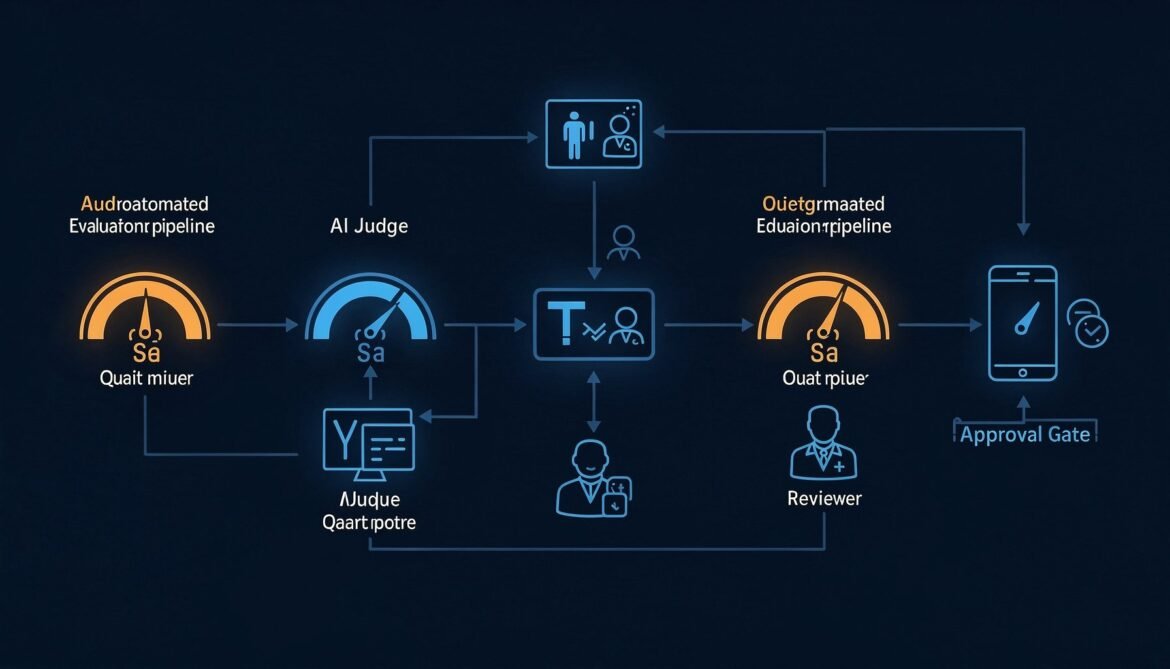
Evaluating LLM Output Quality in Production: LLM-as-Judge and Human Feedback Loops
Tracing and metrics tell you when something is slow or expensive. Evaluation tells you when something is wrong. This post builds a production-grade LLM-as-judge pipeline in Node.js, Python, and C# — with a human feedback loop that catches what automation misses.
LLM Metrics That Actually Matter: Latency, Cost, Hallucination Rate, and Drift
Uptime and error rate are not enough. This post covers the metrics that actually reveal whether your LLM is working correctly in production — time-to-first-token, cost per request, hallucination rate indicators, output drift, and how to build dashboards that catch silent failures before users do.
Why LLMOps Is Not MLOps: The New Operational Reality for AI Teams
Most teams try to apply their existing MLOps practices to LLMs and hit a wall fast. This post breaks down exactly why LLMOps is a different discipline, where the gaps are, and what the new operational stack looks like in production.



