Context engineering is the discipline of designing what goes into your LLM context window, in what order, and how to structure it for maximum cache efficiency, retrieval quality, and cost control. This part covers static-first architecture, cache-aware RAG design, prompt versioning, and token budget management.
Tag: rag

Semantic Caching with Redis 8.6: Vector Similarity Matching for LLM Cost Optimization in Production
Semantic caching operates above the model layer, using vector embeddings to match similar queries to previously computed responses. With Redis 8.6, you can achieve 80 percent or higher cache hit rates without calling the LLM at all. This part covers the full architecture, similarity thresholds, cache invalidation, and production implementations in both Node.js and Python.
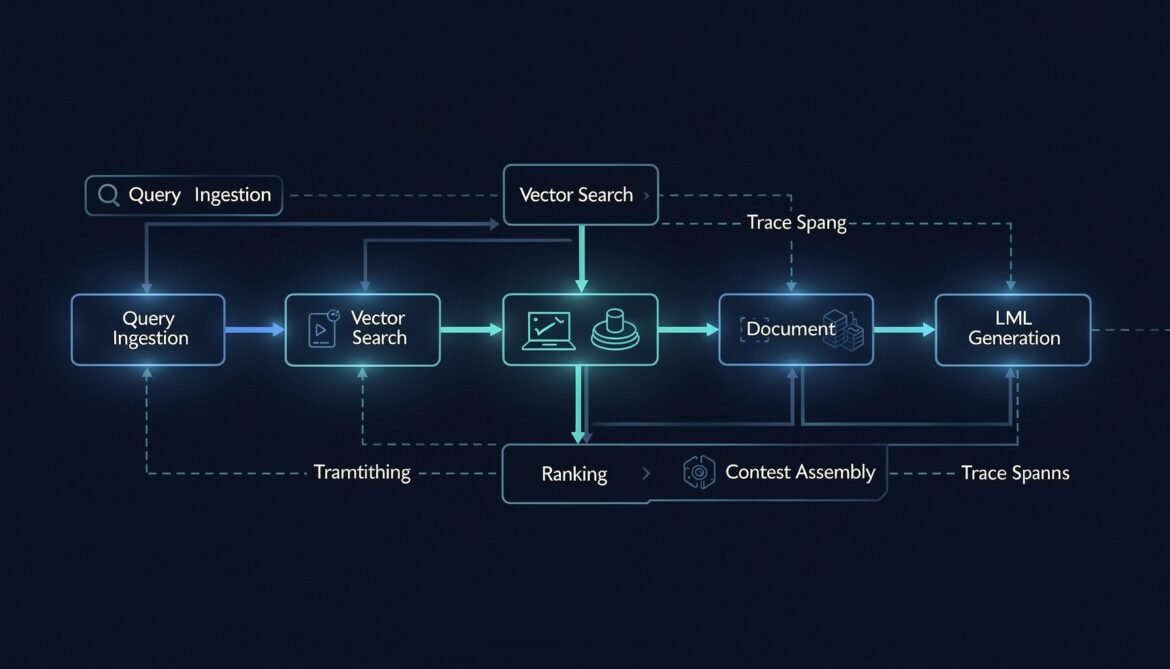
RAG Pipeline Observability: Tracing Retrieval, Chunking, and Embedding Quality
A RAG pipeline has five distinct places it can fail before the LLM ever sees your context. This post instruments every stage — query embedding, vector search, document ranking, context assembly, and generation — with OpenTelemetry spans and quality metrics, in Node.js, Python, and C#.
Building Production RAG Systems with Azure AI Foundry and Claude
Production RAG systems transform Claude from a general-purpose assistant into a domain expert grounded in your enterprise data. Building reliable, scalable RAG architectures in Azure

Vector Databases: From Hype to Production Reality – Part 4: Building RAG Applications on Azure
Theory becomes reality in this part. We move from understanding vector databases and comparing options to actually building a production-ready Retrieval Augmented Generation application on

Vector Databases: From Hype to Production Reality – Part 1: Understanding Vector Databases
The artificial intelligence landscape has undergone a seismic shift in recent years, and at the center of this transformation lies a technology that most developers

Azure AI Foundry in 2025: Building Your First AI Agent in 30 Minutes – Part 2
Build your first AI agent with Azure AI Foundry. Part 2 covers system instructions, RAG implementation, File Search tool configuration, knowledge base upload, and agent testing. Transform your deployed model into an intelligent customer support agent.

Build Your First LangChain Application – Part 6: Creating Retrieval-Augmented Generation (RAG) Chains
Implement Retrieval-Augmented Generation (RAG) to create an AI system that answers questions based on your specific documents. Learn multi-query RAG and conversational capabilities.



