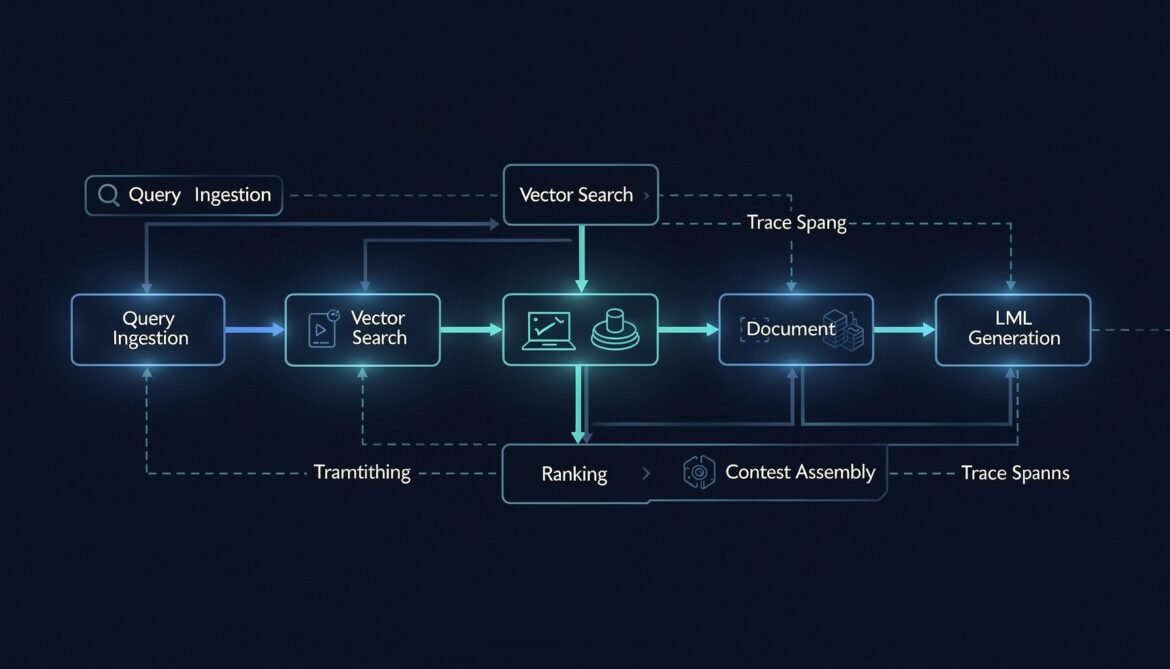
A RAG pipeline has five distinct places it can fail before the LLM ever sees your context. This post instruments every stage — query embedding, vector search, document ranking, context assembly, and generation — with OpenTelemetry spans and quality metrics, in Node.js, Python, and C#.
Tag: Vector Search
Building Production RAG Systems with Azure AI Foundry and Claude
Production RAG systems transform Claude from a general-purpose assistant into a domain expert grounded in your enterprise data. Building reliable, scalable RAG architectures in Azure

Database Integration: MCP for Azure PostgreSQL and pgvector
Throughout this series, we have explored Model Context Protocol fundamentals, Azure MCP Server capabilities, custom server development, and multi-agent orchestration. Now we focus on one



