
Semantic caching operates above the model layer, using vector embeddings to match similar queries to previously computed responses. With Redis 8.6, you can achieve 80 percent or higher cache hit rates without calling the LLM at all. This part covers the full architecture, similarity thresholds, cache invalidation, and production implementations in both Node.js and Python.
Tag: Enterprise AI

Context Caching with Gemini 3.1 Pro and Flash-Lite: Implicit vs Explicit Caching, Storage Costs, and Python Production Implementation
Google Gemini 3.1 Pro and Flash-Lite offer both implicit and explicit context caching, with the most generous default TTL of any major provider at one hour. This part covers how both modes work, how to account for storage costs, and a complete Python production implementation for Vertex AI and the Gemini API.

Prompt Caching with GPT-5.4: Automatic Caching, Tool Search, and C# Production Implementation
GPT-5.4 makes prompt caching automatic with no configuration required. This part covers how OpenAI’s caching works under the hood, how to structure prompts for maximum hit rates, how the new Tool Search feature reduces agent token costs, and a full production C# implementation with cost tracking.
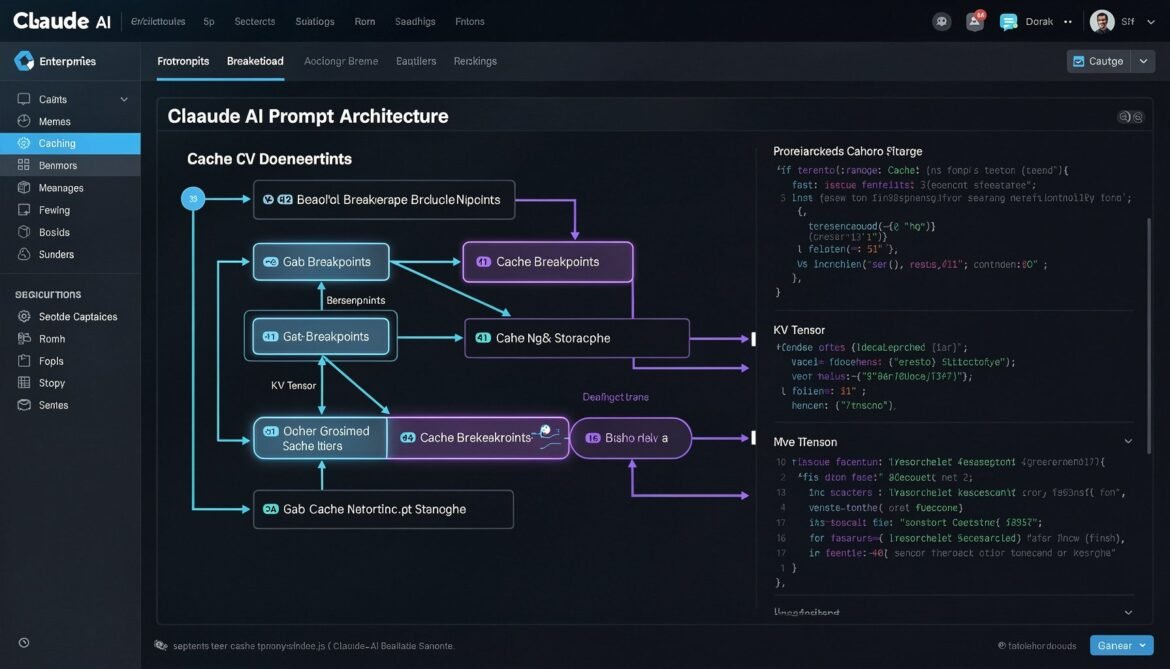
Prompt Caching with Claude Sonnet 4.6: cache_control Breakpoints, TTL Strategies, and Node.js Production Implementation
Claude Sonnet 4.6 gives developers explicit control over prompt caching through cache_control breakpoints. This part covers how to structure your prompts, configure TTL, use multi-breakpoint strategies, and implement a production-ready caching layer in Node.js.
Prompt Caching and Context Engineering in Production: What It Is and Why It Matters in 2026
Prompt caching is one of the most impactful yet underused techniques in enterprise AI today. This first part of the series explains what it is, how it works under the hood, and why it should be a default part of your production AI architecture in 2026.
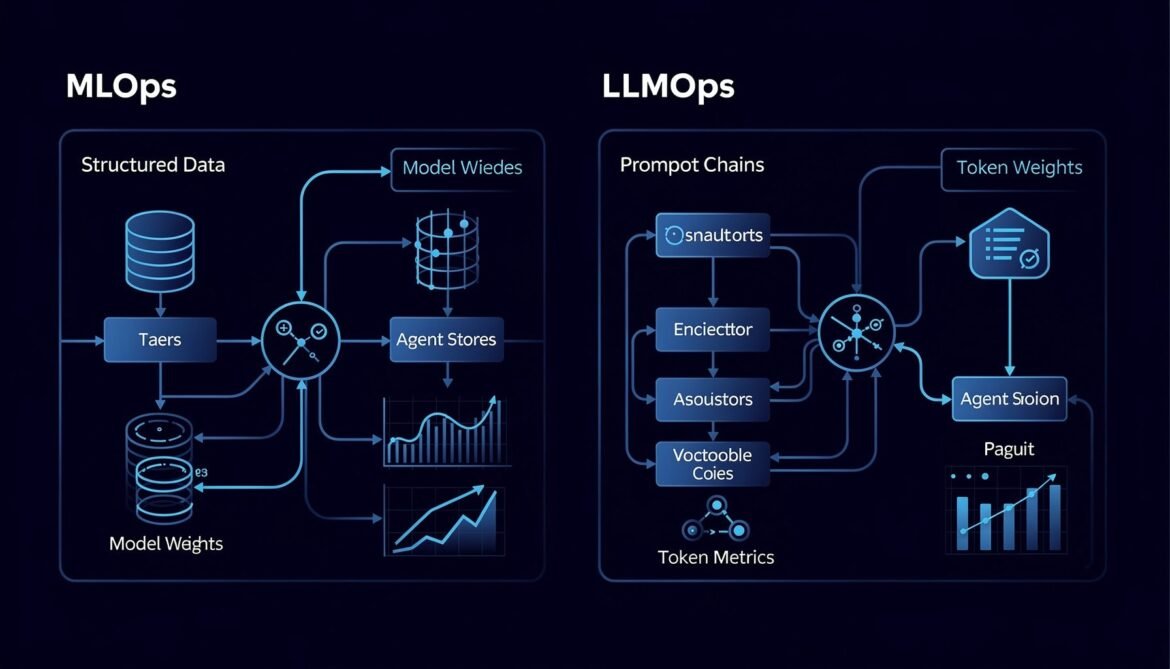
Why LLMOps Is Not MLOps: The New Operational Reality for AI Teams
Most teams try to apply their existing MLOps practices to LLMs and hit a wall fast. This post breaks down exactly why LLMOps is a different discipline, where the gaps are, and what the new operational stack looks like in production.
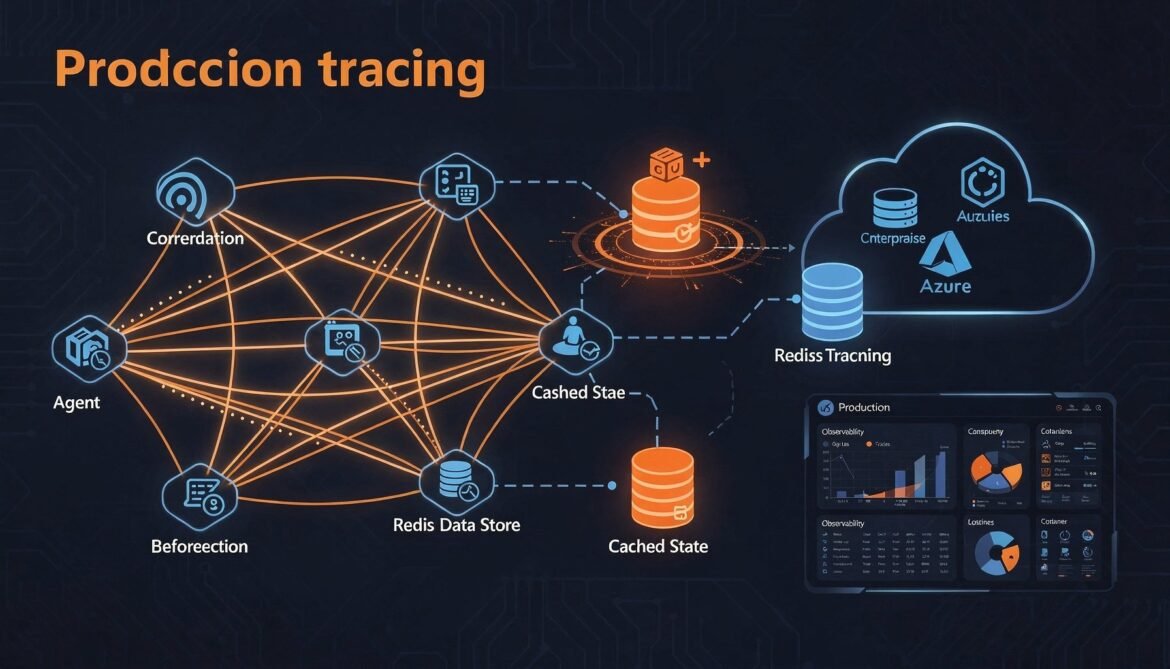
A2A in Production: Observability, Governance and Scaling (Part 8 of 8)
Take your A2A multi-agent system to production. Covers distributed tracing with OpenTelemetry across agent hops, structured logging with trace correlation, Redis-backed task store for horizontal scaling, and deployment on Azure Container Apps.
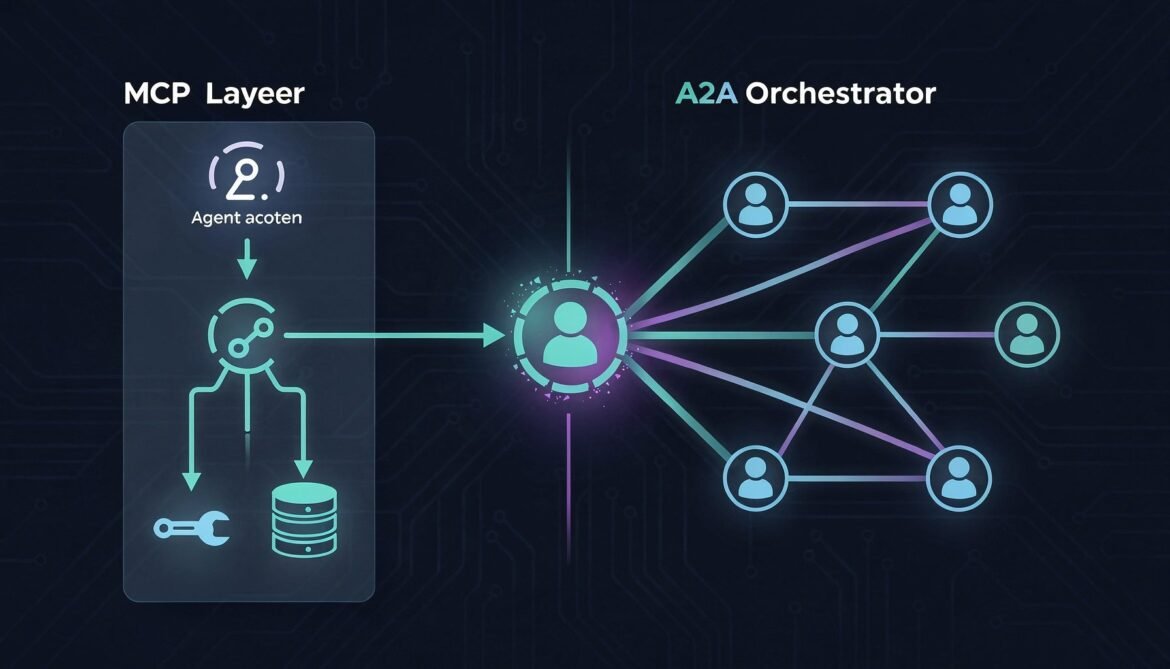
MCP and A2A Together: The Complete Agentic Stack (Part 7 of 8)
Combine MCP and A2A into one unified agentic stack. This post shows exactly where each protocol belongs, how they work together in a real enterprise workflow, and provides a complete Node.js implementation using both simultaneously.

Security, Authentication and Enterprise-Grade A2A (Part 6 of 8)
Harden your A2A agent system for enterprise production. Covers JWT verification, OAuth2 client credentials, mutual TLS, Agent Card signing, RBAC skill-level access control, and a complete security middleware implementation in Node.js.
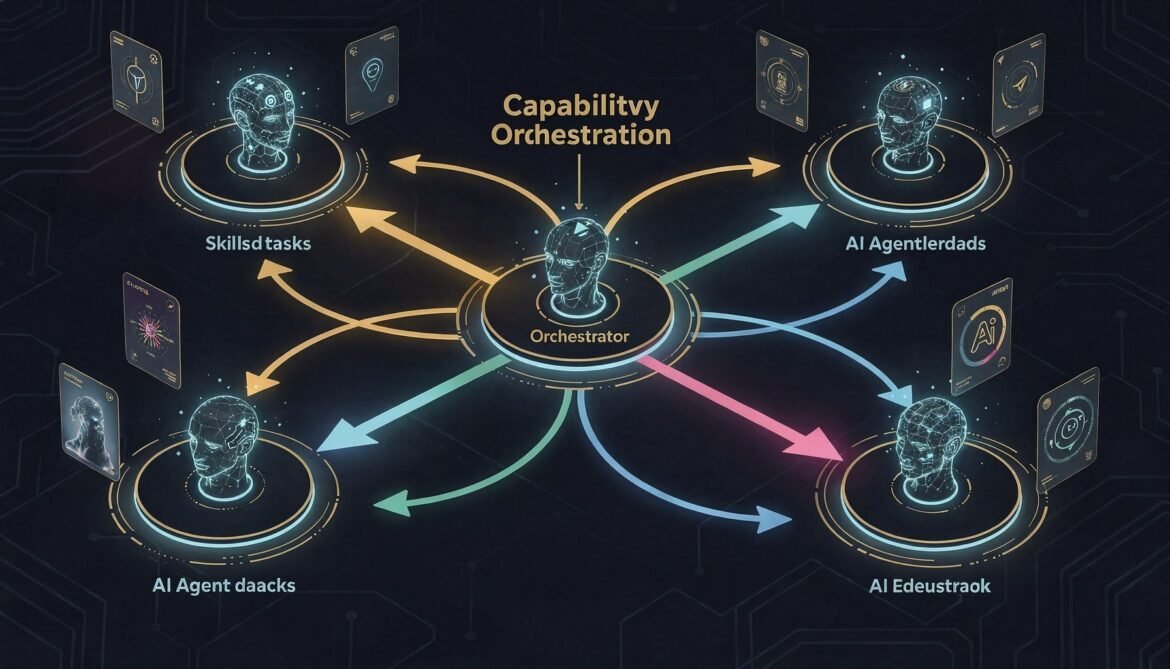
Agent Discovery and Orchestration: Building the Client Agent (Part 5 of 8)
Build the orchestrator layer of an A2A multi-agent system in Node.js. Covers Agent Card fetching, skill-based task routing, concurrent task execution, multi-turn interaction handling, and a complete working orchestrator you can run against the servers from Parts 3 and 4.



