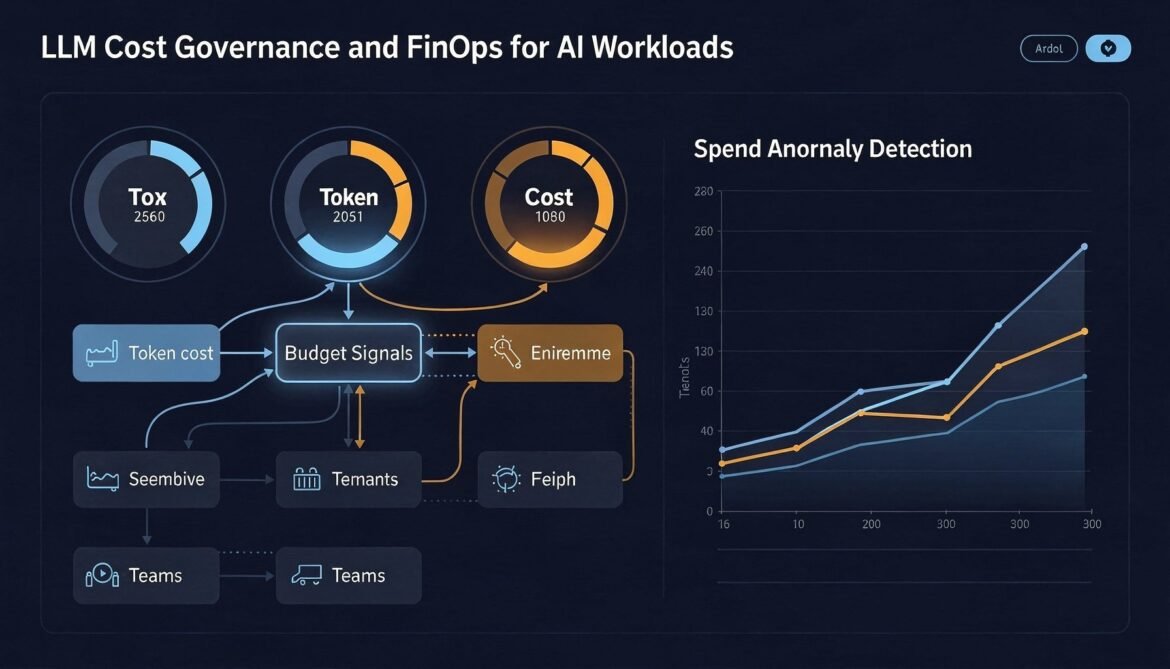
In 2026, inference accounts for 85% of enterprise AI budgets — and agentic loops mean costs can spiral quadratically from a single runaway task. This post builds a complete LLM cost governance system: per-feature attribution, tenant budgets with hard limits, spend anomaly detection, and the optimization levers that cut bills without touching quality.
Category: Observability
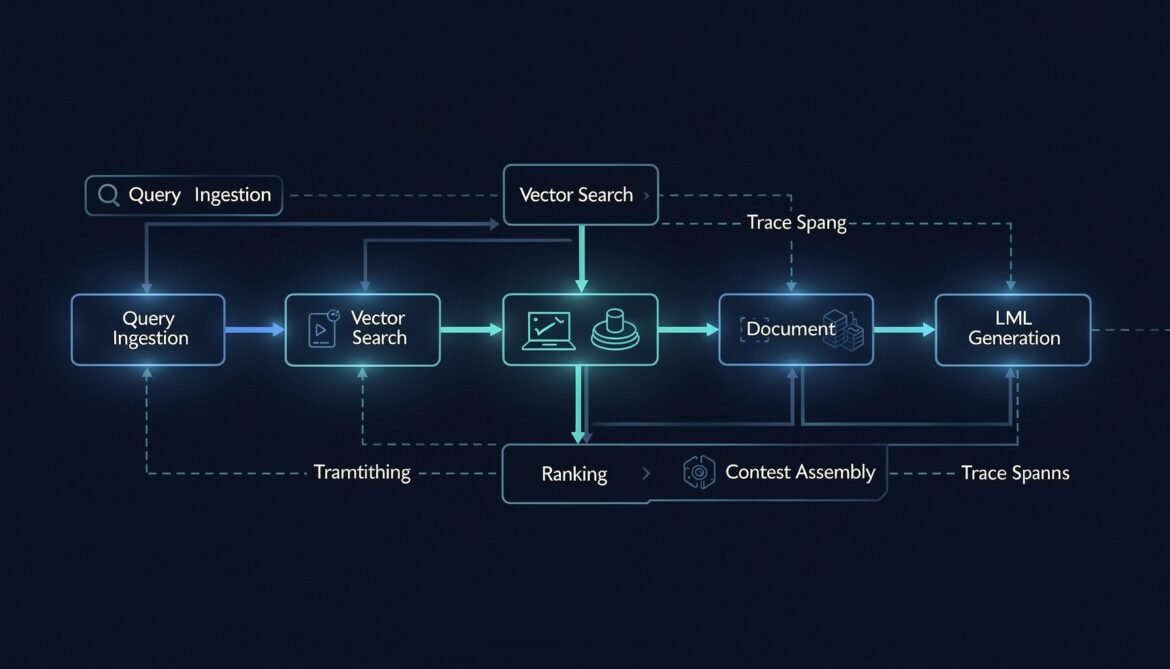
RAG Pipeline Observability: Tracing Retrieval, Chunking, and Embedding Quality
A RAG pipeline has five distinct places it can fail before the LLM ever sees your context. This post instruments every stage — query embedding, vector search, document ranking, context assembly, and generation — with OpenTelemetry spans and quality metrics, in Node.js, Python, and C#.
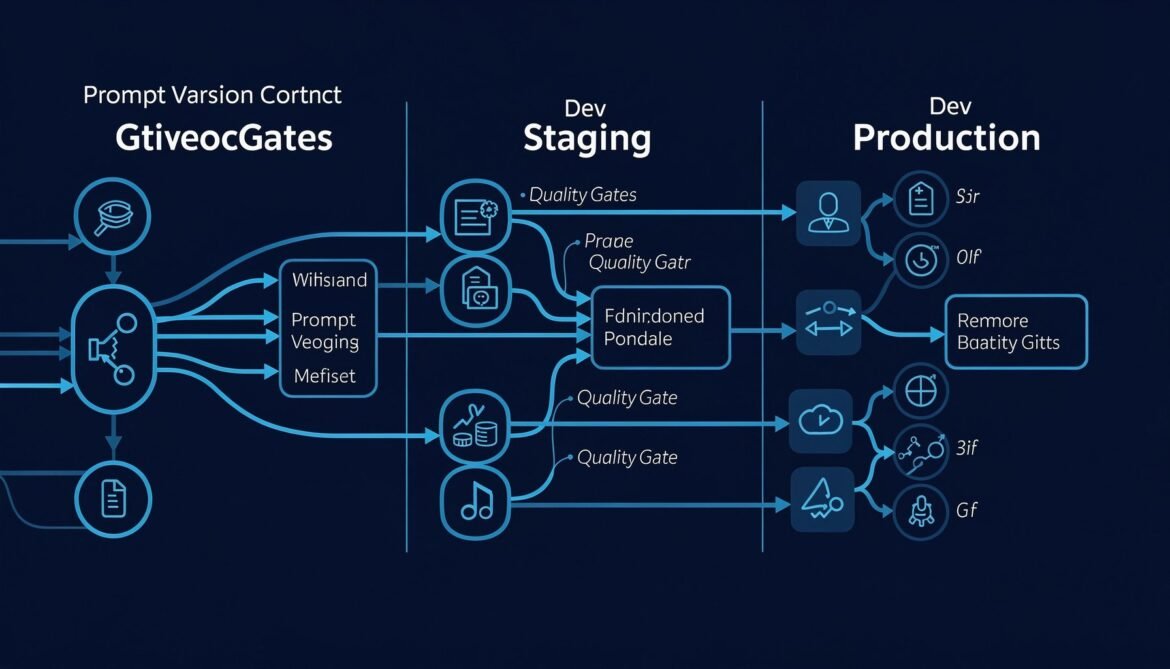
Prompt Management and Versioning: Treating Prompts as Production Code
Prompt changes are production changes. A wording edit at 3pm on a Friday can silently degrade thousands of responses with no error signal. This post builds a production-grade prompt management system with versioning, A/B testing, quality gates, and rollback in Node.js, Python, and C#.
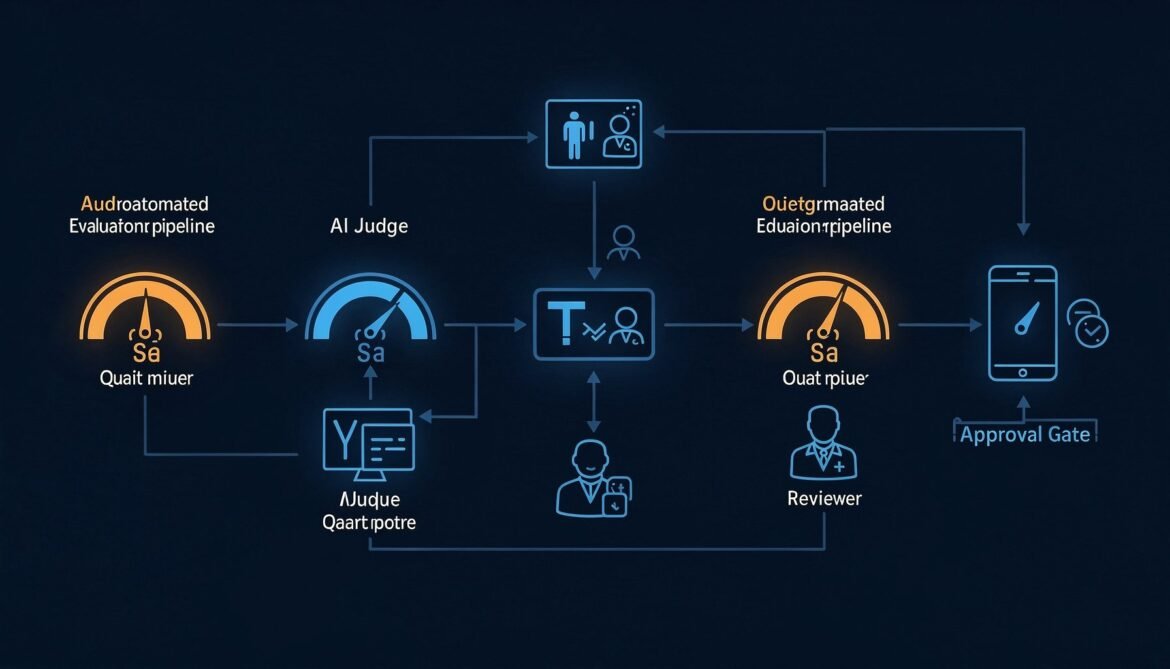
Evaluating LLM Output Quality in Production: LLM-as-Judge and Human Feedback Loops
Tracing and metrics tell you when something is slow or expensive. Evaluation tells you when something is wrong. This post builds a production-grade LLM-as-judge pipeline in Node.js, Python, and C# — with a human feedback loop that catches what automation misses.
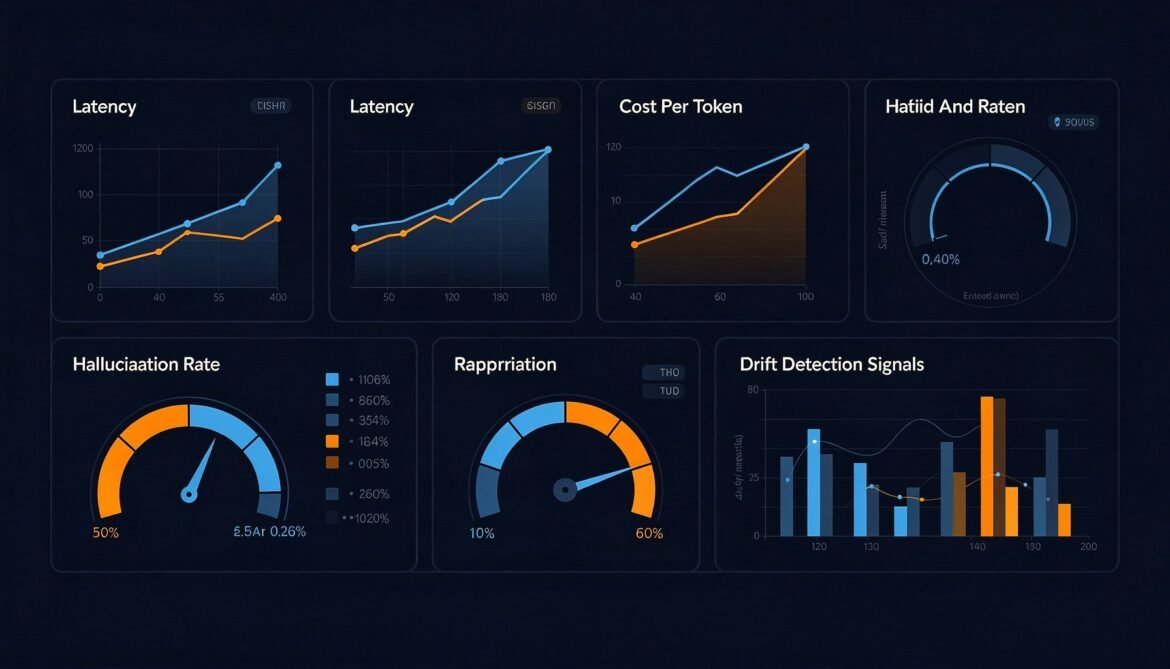
LLM Metrics That Actually Matter: Latency, Cost, Hallucination Rate, and Drift
Uptime and error rate are not enough. This post covers the metrics that actually reveal whether your LLM is working correctly in production — time-to-first-token, cost per request, hallucination rate indicators, output drift, and how to build dashboards that catch silent failures before users do.
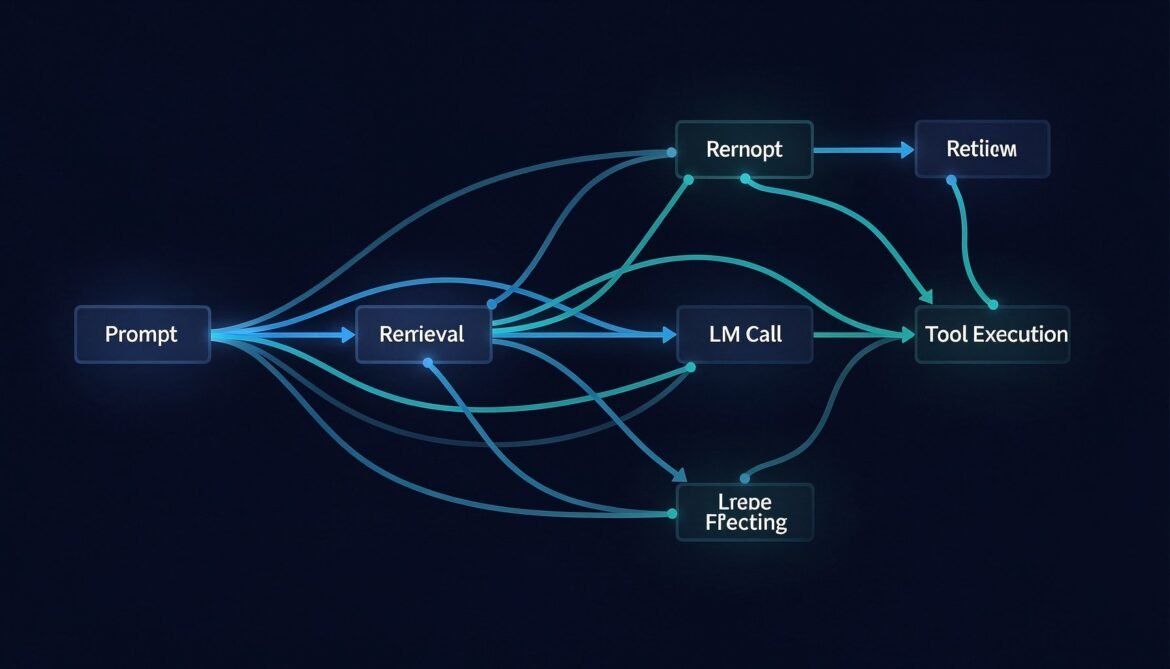
Distributed Tracing for LLM Applications with OpenTelemetry
You cannot fix what you cannot see. This post walks through instrumenting a full LLM pipeline with OpenTelemetry in Node.js, Python, and C# — capturing every span from user request through retrieval, model call, tool execution, and response.
Monitoring, Observability, and Operational Excellence: Building Systems That Tell Their Own Story
Part 7 explores building comprehensive observability that transforms complex systems from black boxes into transparent, self-diagnosing platforms. We dive deep into Azure Monitor, intelligent alerting systems, distributed tracing, and operational excellence practices that enable proactive system management at scale.



