
The first week of April 2026 reshaped the tech industry across four fronts: OpenAI closed a record $122 billion funding round at an $852 billion valuation, Microsoft committed $10 billion to Japan’s AI infrastructure, Meta launched prescription-ready Ray-Ban smart glasses powered by Llama 4, and Cisco unveiled a Zero Trust security framework for autonomous AI agents at RSA 2026.
Category: Cloud Computing
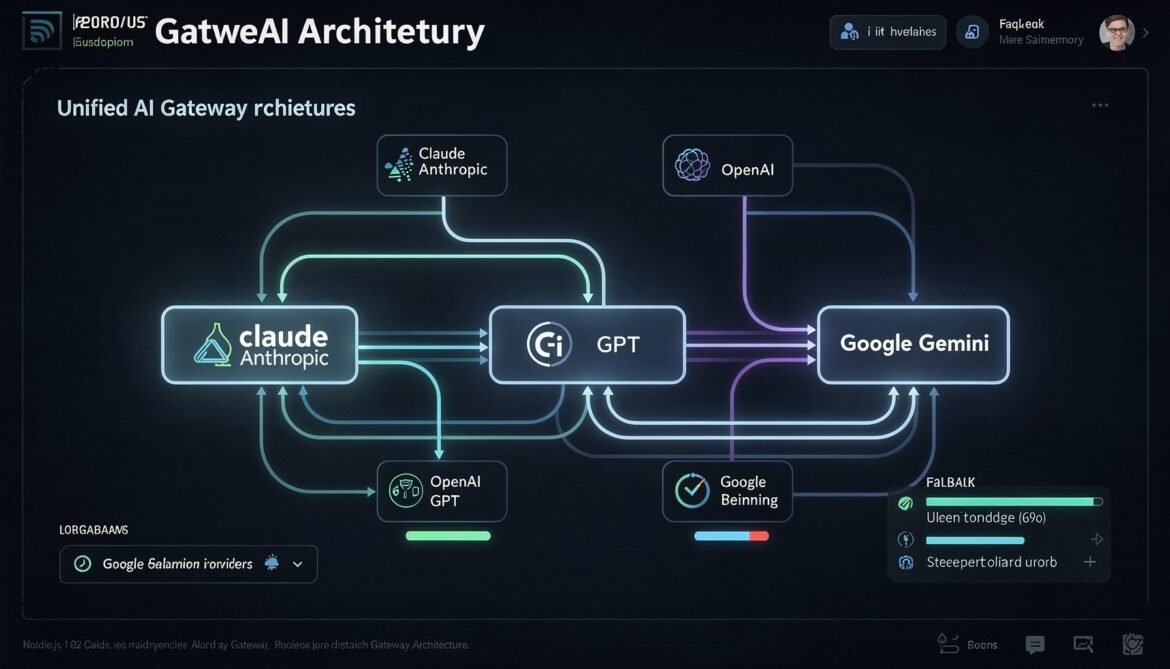
Multi-Provider AI Gateway in Node.js: Unified Caching, Routing, and Fallback for Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro
A unified AI gateway abstracts over provider-specific caching implementations, routing logic, and fallback handling. This part builds a production-ready Node.js gateway that handles Claude Sonnet 4.6, GPT-5.4, and Gemini 3.1 Pro transparently, with cross-provider cost tracking and cache hit monitoring.
Context Engineering Strategies: Designing Prompts for Cache Efficiency, RAG Pipelines, and Production Scale
Context engineering is the discipline of designing what goes into your LLM context window, in what order, and how to structure it for maximum cache efficiency, retrieval quality, and cost control. This part covers static-first architecture, cache-aware RAG design, prompt versioning, and token budget management.

Semantic Caching with Redis 8.6: Vector Similarity Matching for LLM Cost Optimization in Production
Semantic caching operates above the model layer, using vector embeddings to match similar queries to previously computed responses. With Redis 8.6, you can achieve 80 percent or higher cache hit rates without calling the LLM at all. This part covers the full architecture, similarity thresholds, cache invalidation, and production implementations in both Node.js and Python.

Context Caching with Gemini 3.1 Pro and Flash-Lite: Implicit vs Explicit Caching, Storage Costs, and Python Production Implementation
Google Gemini 3.1 Pro and Flash-Lite offer both implicit and explicit context caching, with the most generous default TTL of any major provider at one hour. This part covers how both modes work, how to account for storage costs, and a complete Python production implementation for Vertex AI and the Gemini API.

Prompt Caching with GPT-5.4: Automatic Caching, Tool Search, and C# Production Implementation
GPT-5.4 makes prompt caching automatic with no configuration required. This part covers how OpenAI’s caching works under the hood, how to structure prompts for maximum hit rates, how the new Tool Search feature reduces agent token costs, and a full production C# implementation with cost tracking.
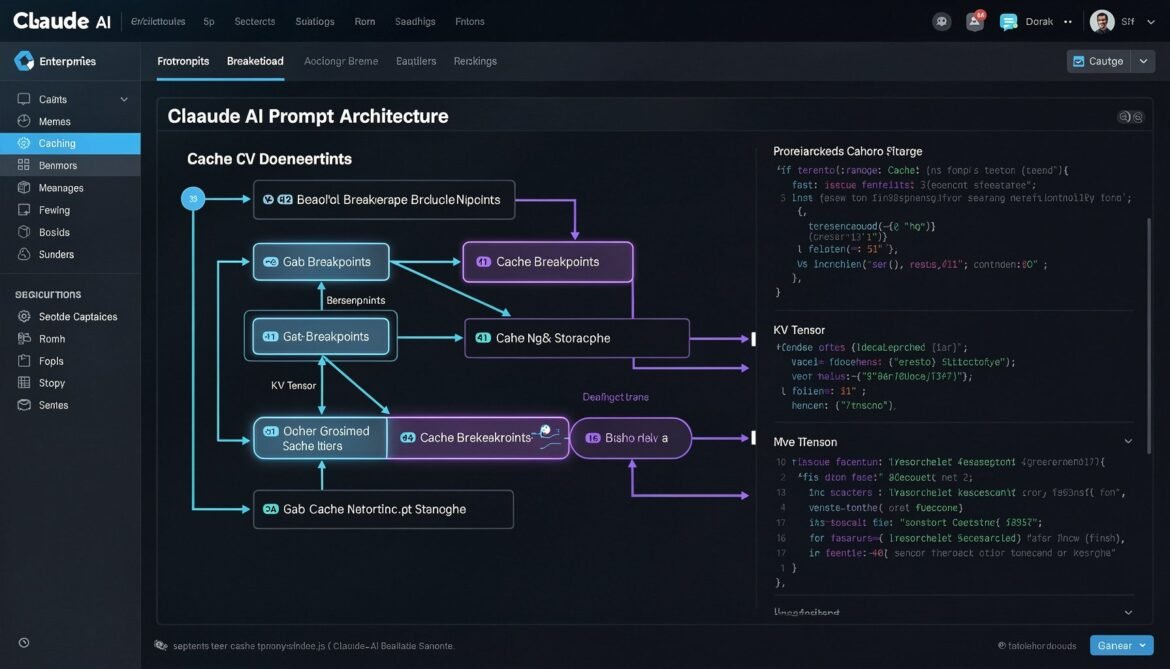
Prompt Caching with Claude Sonnet 4.6: cache_control Breakpoints, TTL Strategies, and Node.js Production Implementation
Claude Sonnet 4.6 gives developers explicit control over prompt caching through cache_control breakpoints. This part covers how to structure your prompts, configure TTL, use multi-breakpoint strategies, and implement a production-ready caching layer in Node.js.
Prompt Caching and Context Engineering in Production: What It Is and Why It Matters in 2026
Prompt caching is one of the most impactful yet underused techniques in enterprise AI today. This first part of the series explains what it is, how it works under the hood, and why it should be a default part of your production AI architecture in 2026.

Enterprise AI Infrastructure: Gateways, MLOps, and Production Architecture
Production-grade AI systems require sophisticated infrastructure that goes far beyond simply calling API endpoints. As enterprises transition from experimental pilots to production deployments, they must

Breaking Out of Pilot Purgatory: The Production AI Challenge in 2026
The artificial intelligence industry has reached a critical inflection point in 2026. After years of experimental pilots and proof-of-concept projects, enterprises are facing mounting pressure



